

导读 阿里云大数据开发治理工具 DataWorks从2009 年发展至今,已经有14年的发展历程。2021年云栖大会上,DataWorks 全新推出数据建模工具 DataWorks 智能数据建模。同 DataWorks 数据开发等产品模块相同,智能数据建模的产品建设离不开阿里巴巴内部各业务线的数据仓库团队,如菜鸟、淘宝、天猫等数据仓库团队的贡献。本文将分享阿里云 DataWorks 智能数据建模在产品建设过程中的一些思考。
文章主要包括四大部分:
1.阿里巴巴数据需求流转介绍
2.阿里巴巴数仓建模最佳实践
3.阿里巴巴数仓建模实操演示
4.数据模型应用-数据资产介绍
分享嘉宾|爱桐 DataWorks 产品专家
编辑整理|罗庆新
内容校对|李瑶
出品社区|DataFun
01 阿里巴巴数据需求流转介绍
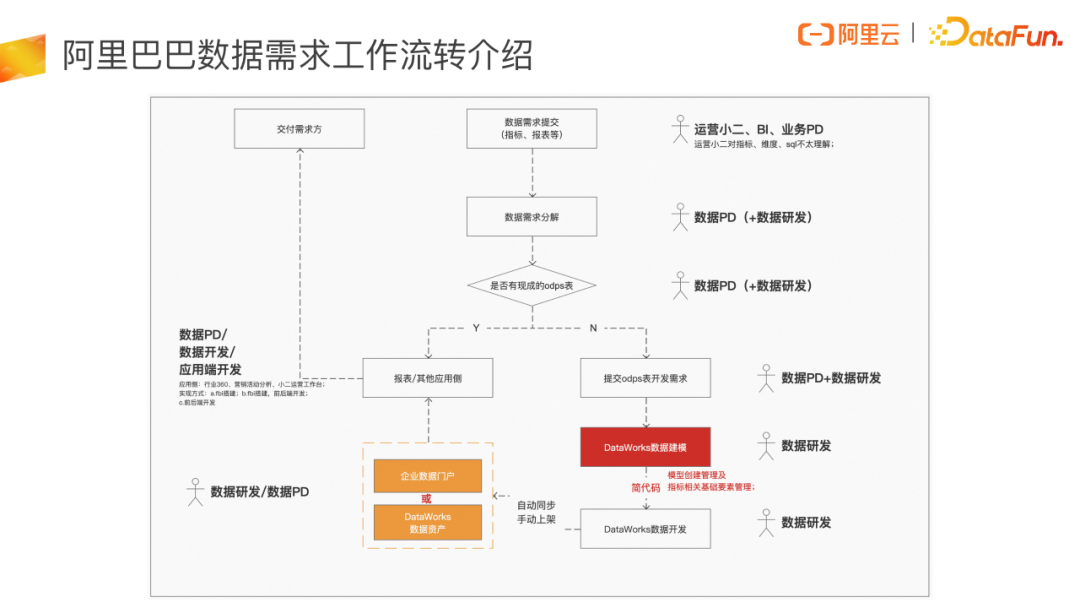
数据仓库建设过程中通常会有以下几类角色参与:
- 数据需求方:包括运营同学、BI、业务产品经理等业务角色,这类角色对数据概念了解甚少,可能也不知道模型、表、派 生指标等专业数据名词,但这类角色往往都是业务专家,对业务情况非常了解。
- 数据产品经理:阿里内部大部分 BU 都会有数据产品经理这个角色,他们负责把业务需求转化为能实际进行数据开发的数据需求。这也就意味着数据产品经理本身的要求是既需要对所负责的业务策略要非常地了解,也需要数据开发工作非常了解。
- 数据开发工程师:数据研发工程师主要负责数据模型、数据指标的设计以及相应的数据研发工作。
02 阿里巴巴数仓建模最佳实践
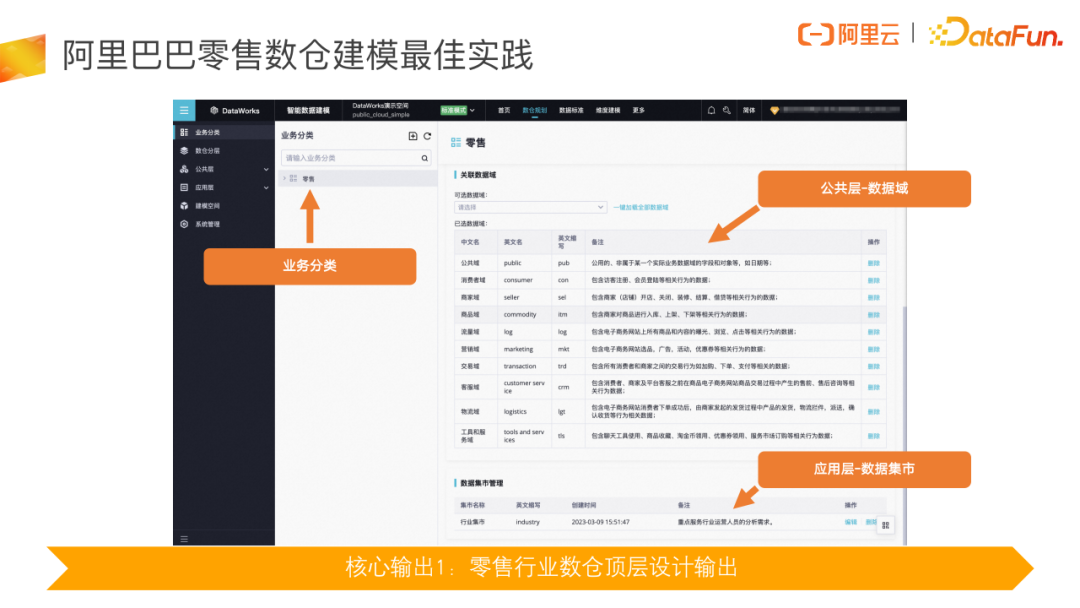
- 业务分类:阿里巴巴大多数数仓团队都是基于 Kimball 理论做维度建模,其更注重公共层和应用层的建设。由于涉及到的业务体系较为庞大,为了能够更好的各模型所属业务团队,我们在维度建模理论的基础上,我们增设了“业务分类”,它从更高的视角把不同业务团队的数据仓库区分开来。
- 数据域:是公共层里非常重要的一个概念。在设置数据域时,我们往往会先划分好业务流程,通过将业务流程进行聚合形成一部分数据域,然后我们再将整个业务中重要的参与对象或系统梳理出来形成另外一部分数据与,从而形成完整的数据域。
- 数据集市:是应用层里非常重要的一个概念。应用层是否建模,实际上要应业务自身发展情况而定,可以选择应用层建模、部分建模或者不建模。数据集市又可以分为业务集市、数据产品集市和公共集市。
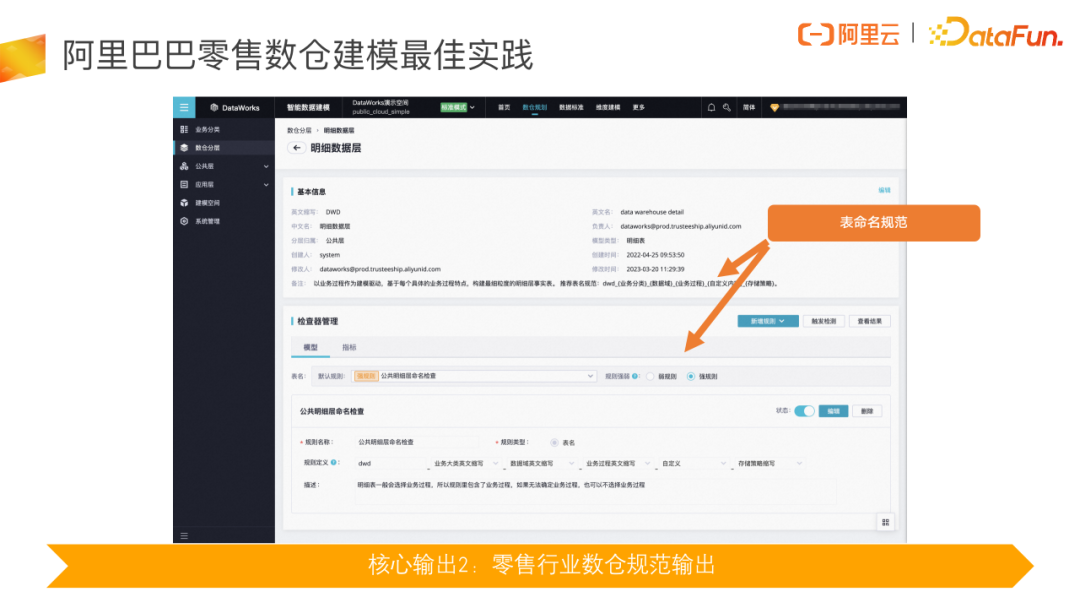
除了刚才讲到的数仓顶层设计外,数据规范的制定与执行,也是整个数仓建设过程中最难的点。数据规范,如表名规范到底应该怎么去建,我们也有已经将其以内容呈现的方式,内置在我们的零售行业模型模版中。诸如字段命名规范、存储策略的规范命名等,我们也都以内容内置、输入检测、提交卡点等形式体现在产品中,在最大程度上保证规范的落地。
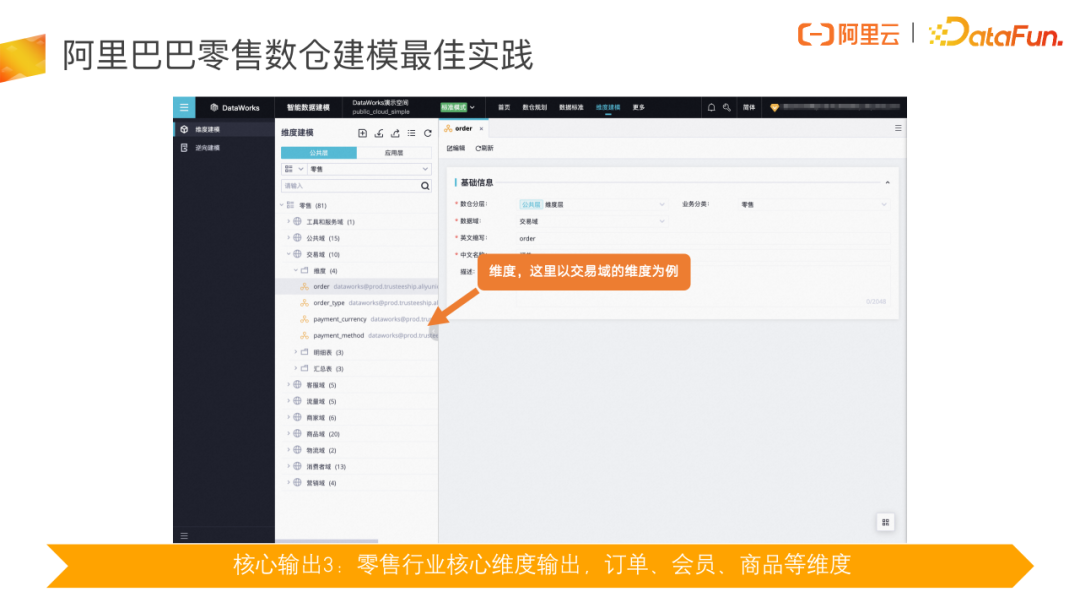
在维度建模理论中,维度是一个非常重要的概念,维度是我们观察业务状况的视角,建立整体统一的维度,有助于后续各种业务分析工作的开展。例如交易域的维度包含订单、订单类型、订单支付类型等。
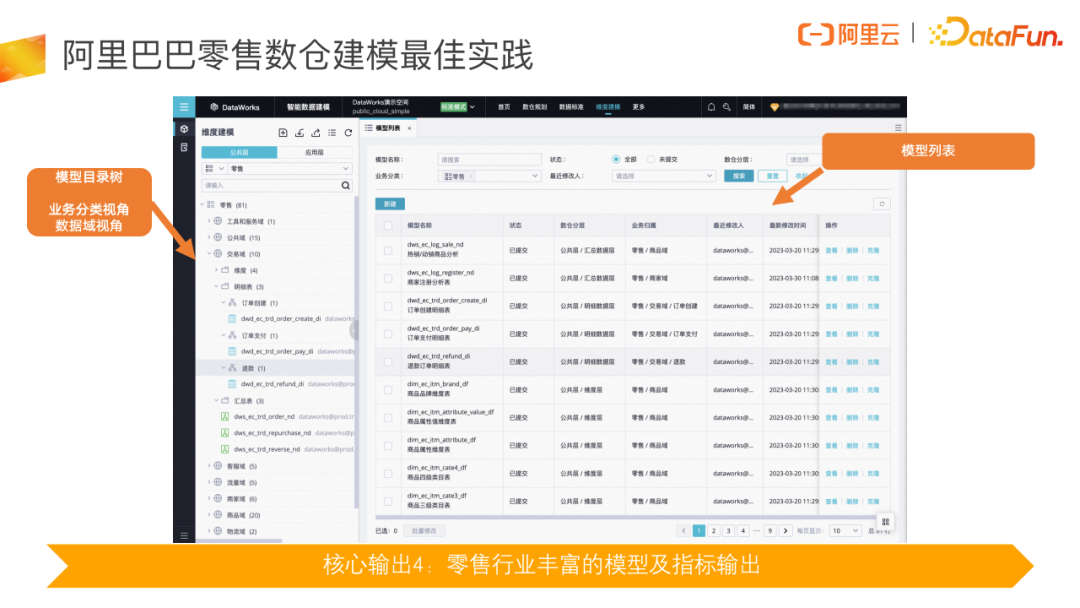
由于数据建模的使用具备一定的理论门槛,DataWorks 智能数据建模工作提供开箱即用的零售行业数据仓库模型内容,涵盖大部分分层划域,涉及订单、会员、商品等维度及大部分的模型和指标。模型导入后,在当前页面可以完整地看到这些模型及指标。
03 阿里巴巴数仓建模实操演示
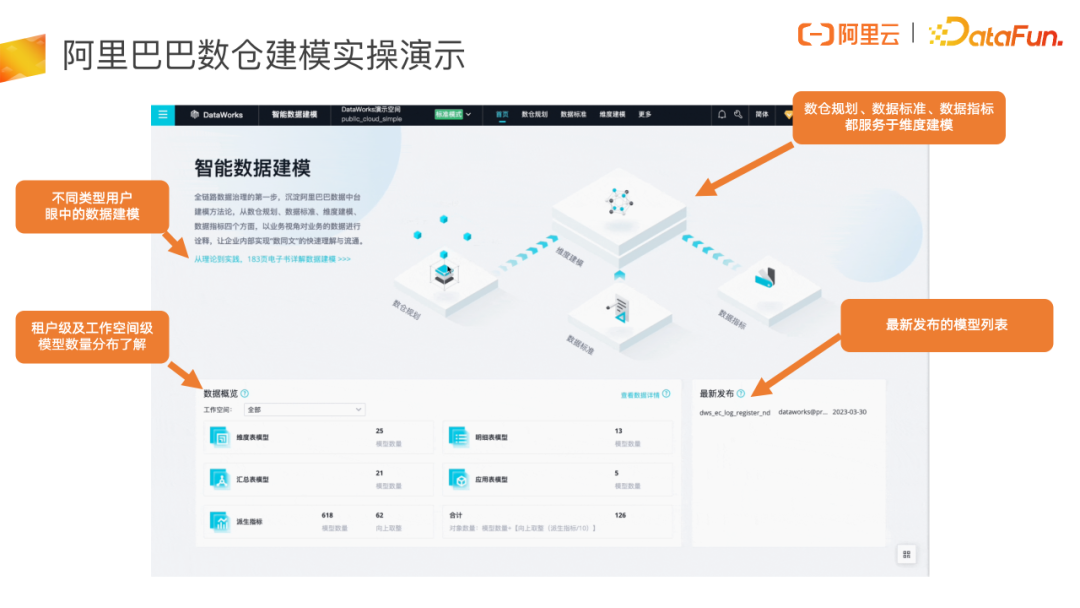
接下来我会带大家一起做一个数据仓库模型设计的实操演示。数据建模主要有四方面的工作:数仓规划、数据标准、数据指标和维度建模。在日常的建模工作中,架构师先定义好数仓规划、数据标准、原子指标修饰词,再由模型设计师和数据研发同学把模型和指标创建好。和建模分工一致,DataWorks 智能数据建模在产品设计上,数仓规划、数据标准和数据指标也最终都是服务于维度建模。
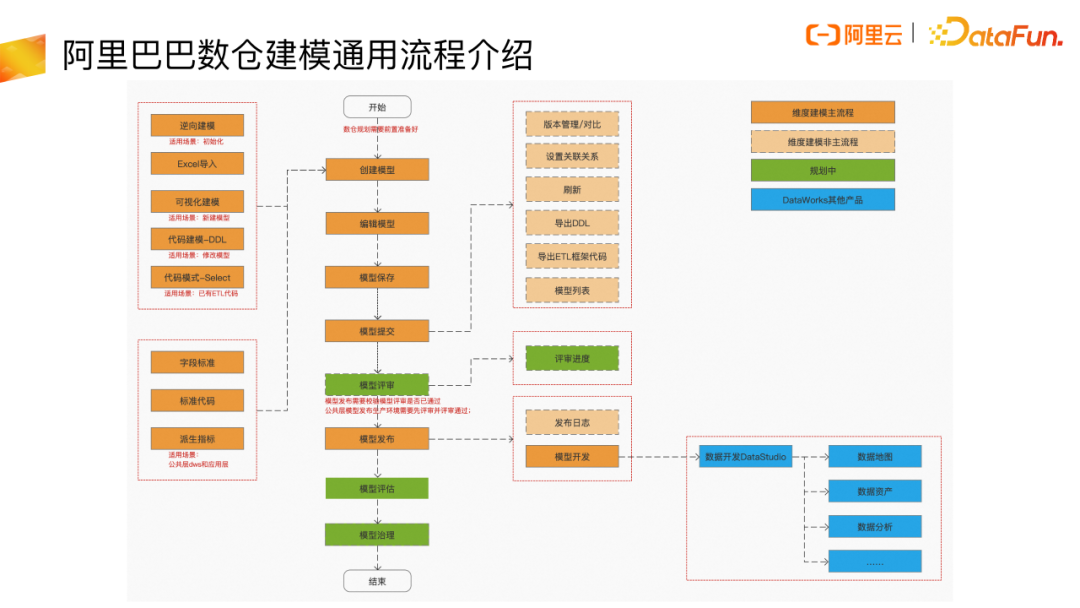

现在我们一起看一下,整个数仓建模实践过程中,大家可能都会遇到的一些问题。
- 建模冷启动难的问题:对于大部分想要做好模型设计工作的数据仓库团队来说,在模型设计初期,可能会面临很多的历史包袱。
- 规范落地难的问题:规范制定非常难,制定好之后落地也很难。我们之前经常会发现没有按照规范去做研发,导致了很多额外的沟通。
- 建模效率低的问题:从不建模到建模,日常建模方式一定会有效率的降低。
- 模型设计和数据研发脱节的问题:阿里内部数据研发的模型设计更多是用线下的 Excel,这种方式对数据研发阶段来讲,能获取的帮助不是特别多,衔接的体验就会较差。
下面来具体展开介绍每一个问题的解决方法。
问题1:如何解决已有数仓建模冷启动难的问题?
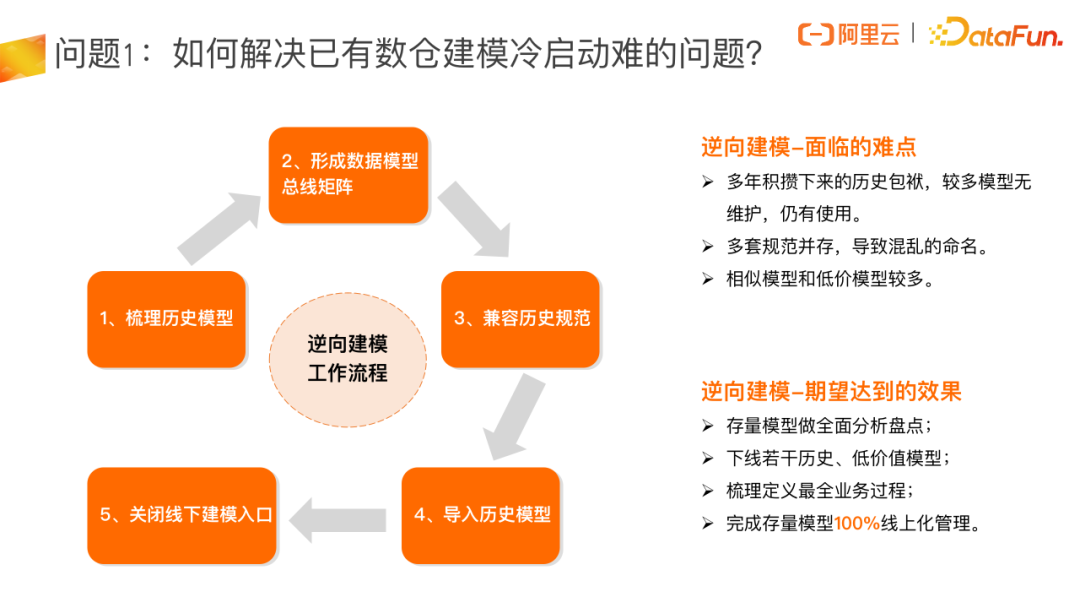
由于历史原因,很多模型没法维护,还存在很多相似的模型或低价值的模型,很多模型没有在用了,但存储还在。我们希望大家能够做一次历史模型的线下梳理,梳理出来后(我们称为全面分析盘点),下线历史上没有用的或者相似的模型。
对相似模型处理完成后,会形成一个数据模型的总线矩阵,这个总线矩阵需要去兼容一些历史规范问题,我们可以借此把整个总线矩阵梳理好,最后通过产品的方式把历史存量的模型导入到产品里,也就完成了存量模型的线上化管理。最终线下模型处理好之后,存量模型开始正常在产品上做建模之前,我们会把线下建模的口子关掉,从而保障模型后续都是比较规范的。
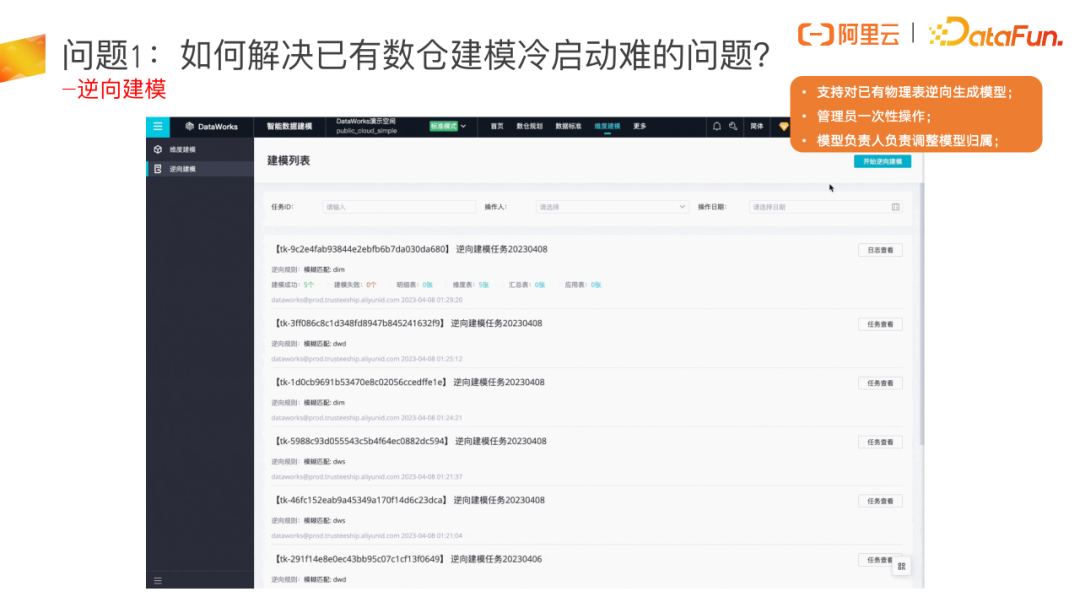
大多数架构师会通过 DataWorks 逆向建模把已经线下治理好的存量模型一次性批量导入到 DataWorks 产品里,导入后再去正向建模或修改。这里我们建议最好是做好线下梳理之后再使用这个功能。
问题2:如何解决数仓规范落地难的问题?
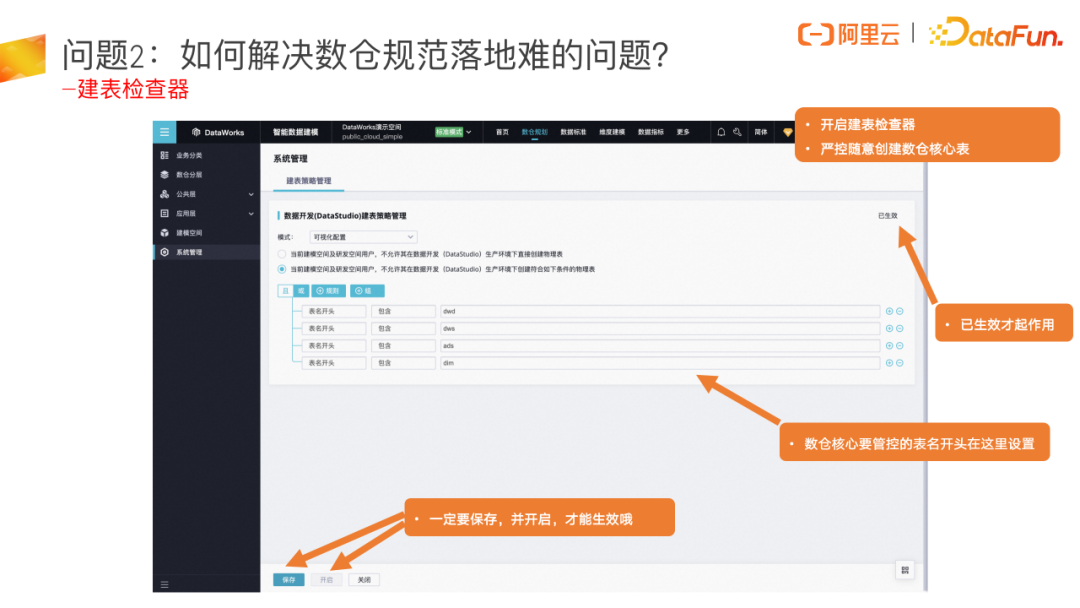
逆向建模之后一个很重要的工作就是去关掉线下所有能够去建模的口子,我们的做法是在系统里把建模检查器配置好,其作用是后续所有人要去开发数仓核心表时,必须要建模,不能直接上线。
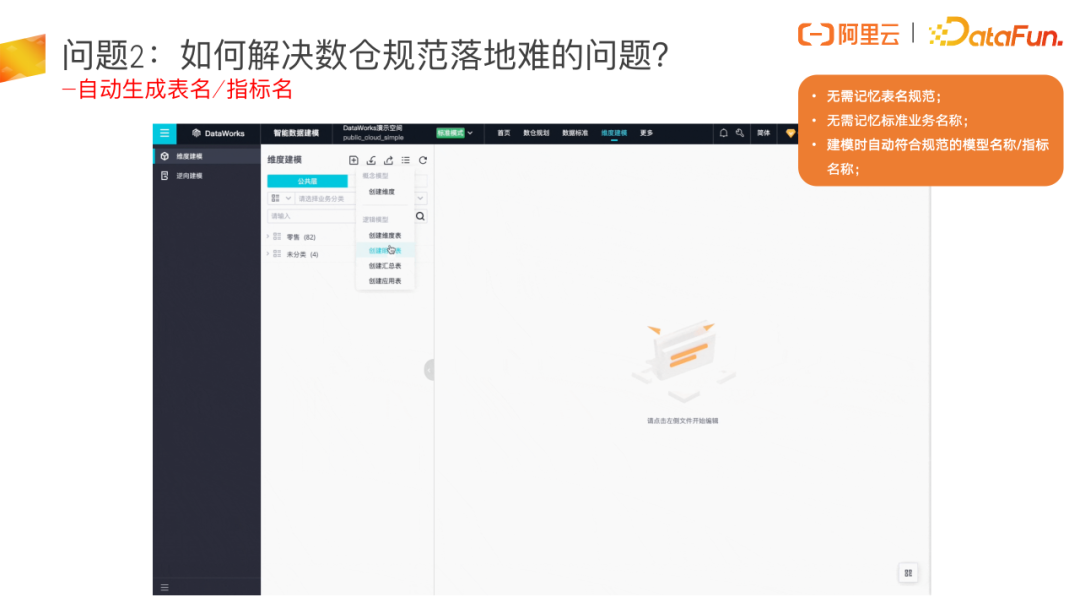
规范落地比较典型的场景是表名规范,过去大家需要记表名规则是什么,规则里的每个词到底应该怎么写,而现在已经完全产品化,模型设计师新建一个模型时,会调用对应分层下的模型命名规则,把表名自动生成出来,直接避免了模型命名不规范的情况出现。
问题3:如何提升模型设计的工作效率?
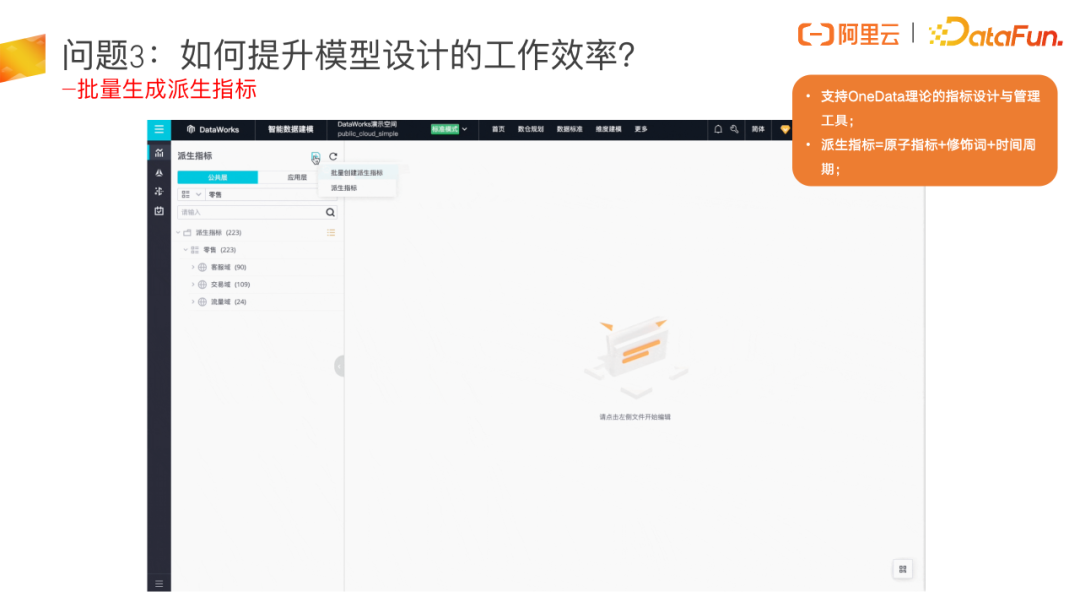
在指标设计方面,最重要的一个点是通过勾选原子指标、修饰词、时间周期批量生成派生指标,生成后再做汇总层模型和应用层模型建设,效率就会高很多。
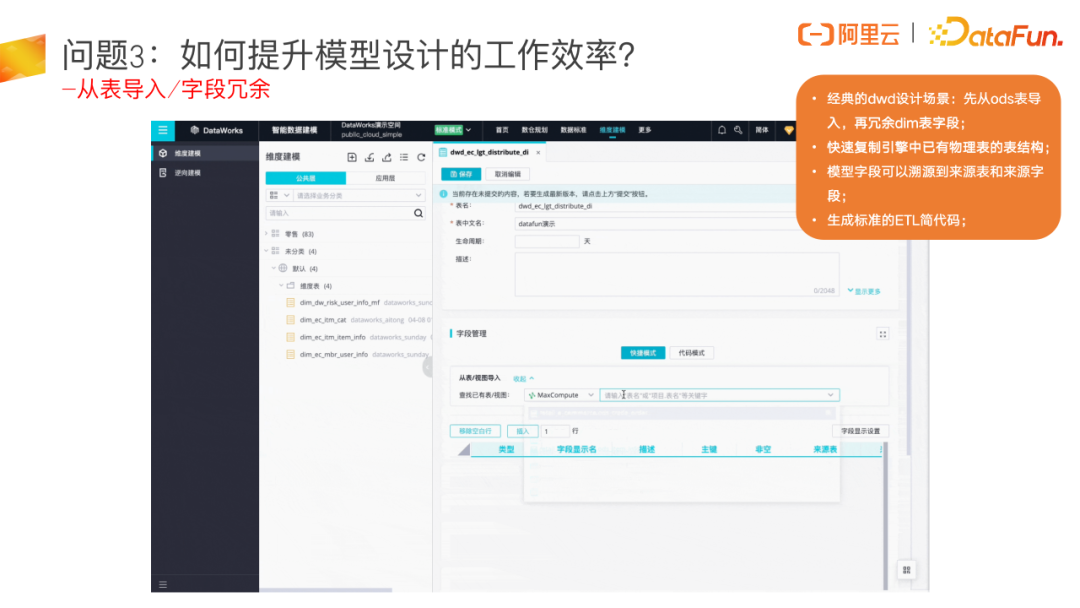
在数据模型创建时,一个经典的建模场景是从表导入再字段冗余。以明细表模型创建为例,DWD 会基于 ODS 的数据表结构,直接导入,基本上不会做改变,只是基于这个基础做一些脏数据处理,然后再把经常需要分析的维度冗余到 DWD 这张表里来,这时就可以快速完成 DWD 的模型设计。
通过这样的建模方式后续生成的 ETL 代码就会非常规范。基本上只需要添加一下 where 条件以及 case when等就可以了。
对于汇总表和应用表,通常是直接从指标导入,把数据指标中创建好的派生指标直接导入到模型字段里来,指标名称直接作为字段名称,这样后续应用理解上也非常方便,而且也能够统一。
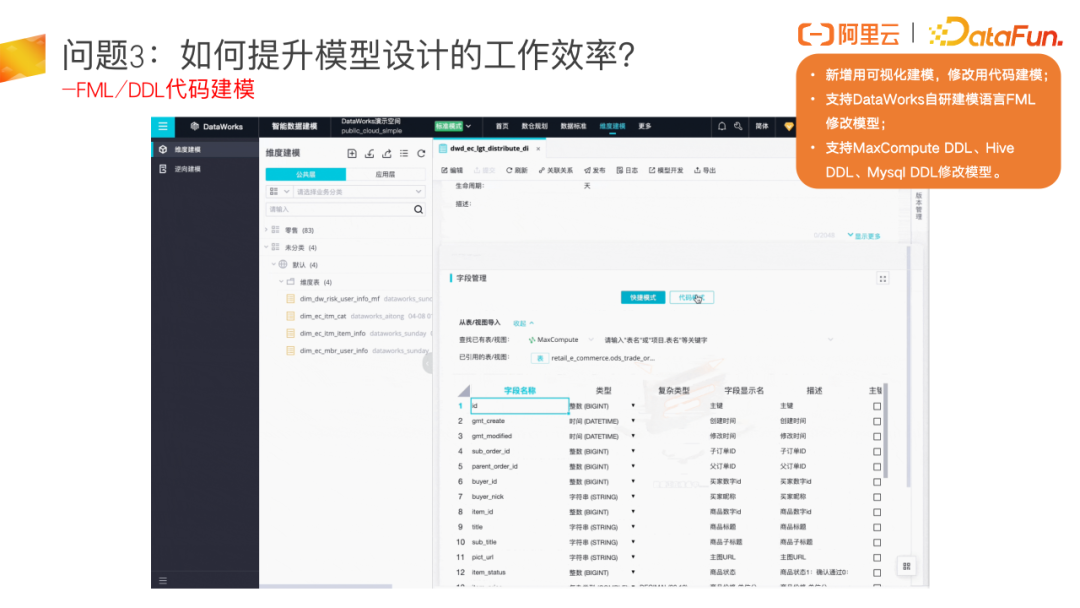
上述介绍的是新建模型的场景,如果要修改模型,建议通过代码建模,代码模式会支持常用的 MaxCompute DDL、Hive DDL 等。
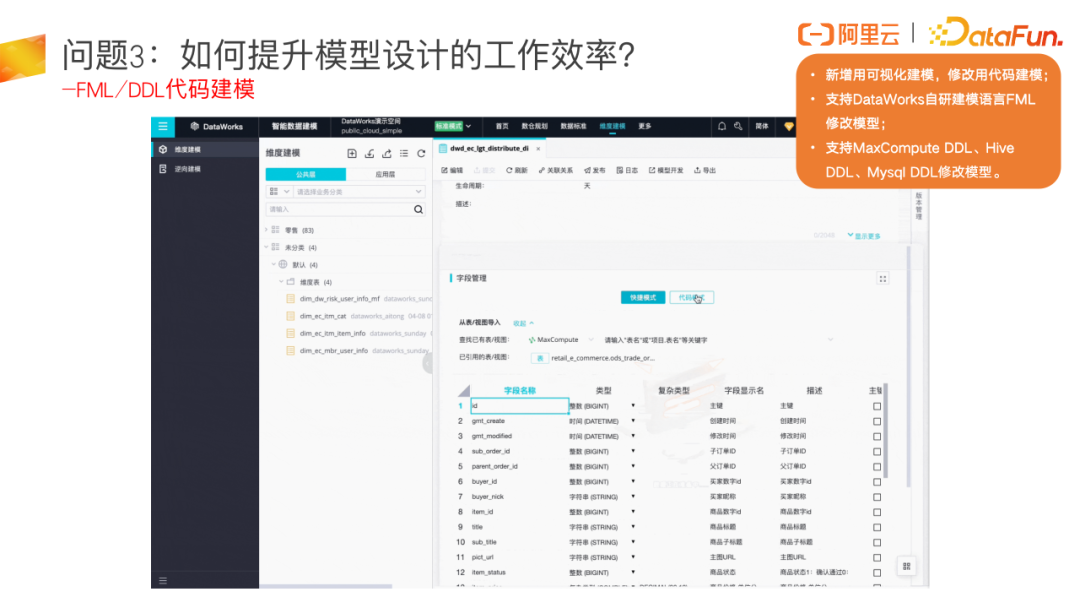
在代码模式中,我们也支持根据 select 语句快速生成模型,这个功能非常适用于平时喜欢先分析数据,写好 ETL 代码,再去做模型设计的场景。
问题4:如何解决模型设计与数据研发脱节的问题?
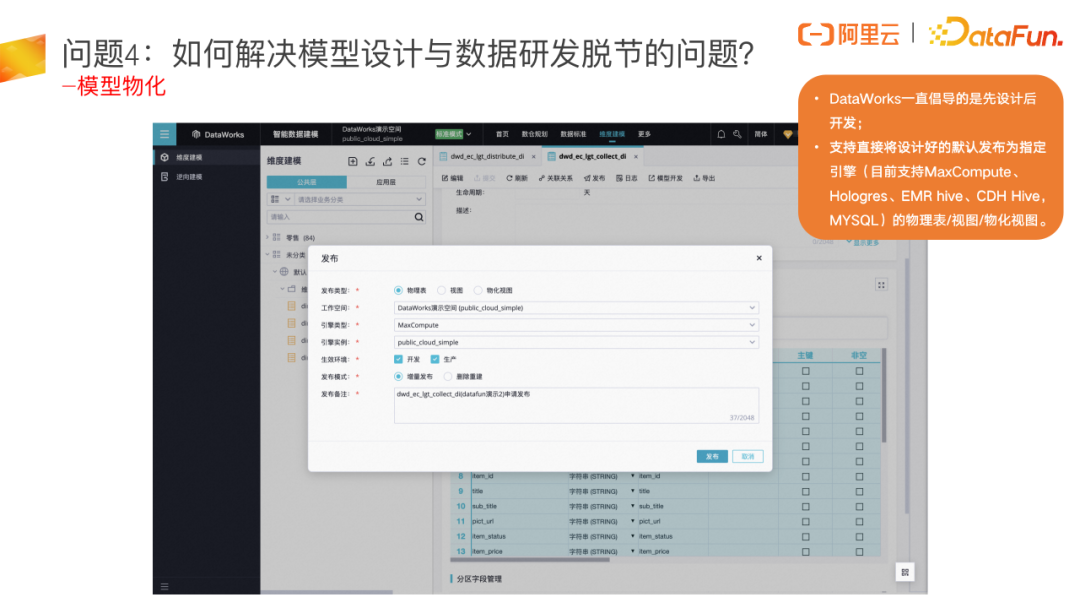
大家对直接创建物理表的方式可能会比较熟悉,在 DataWorks 智能数据建模中创建模型再进行物化时,无需再编写 DDL 语句,可直接将模型发布为物理表,只要在产品上选要发布到哪里、发布到哪个环境等即可。
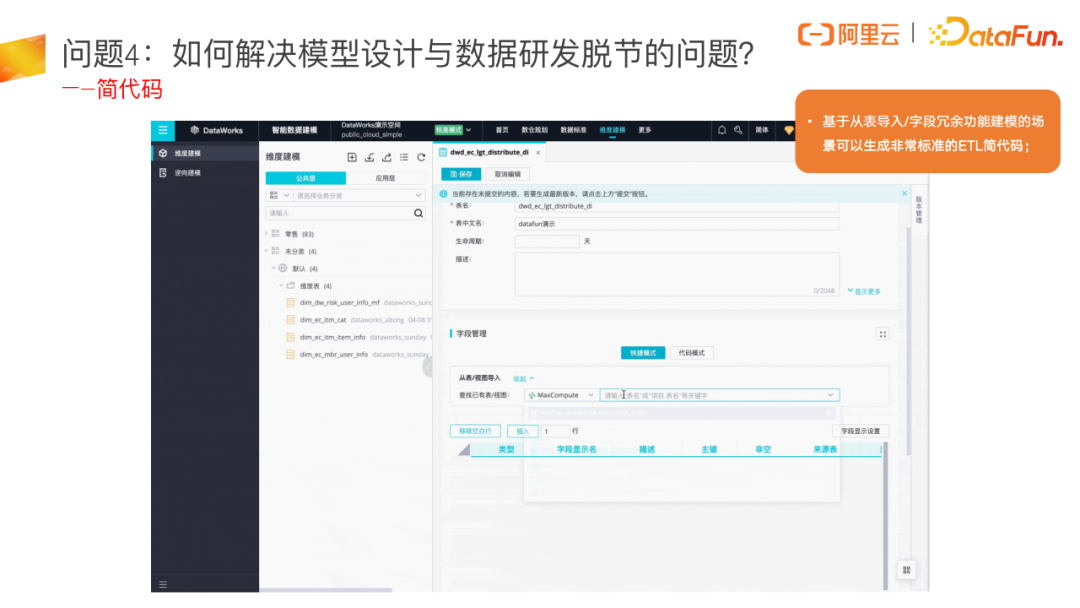
简代码打通了模型设计和数据研发,先做好模型设计后,可以通过模型的数据开发功能,自动生成模型对应的 ETL 代码,并打通数据开发,将代码加载到数据开发中。
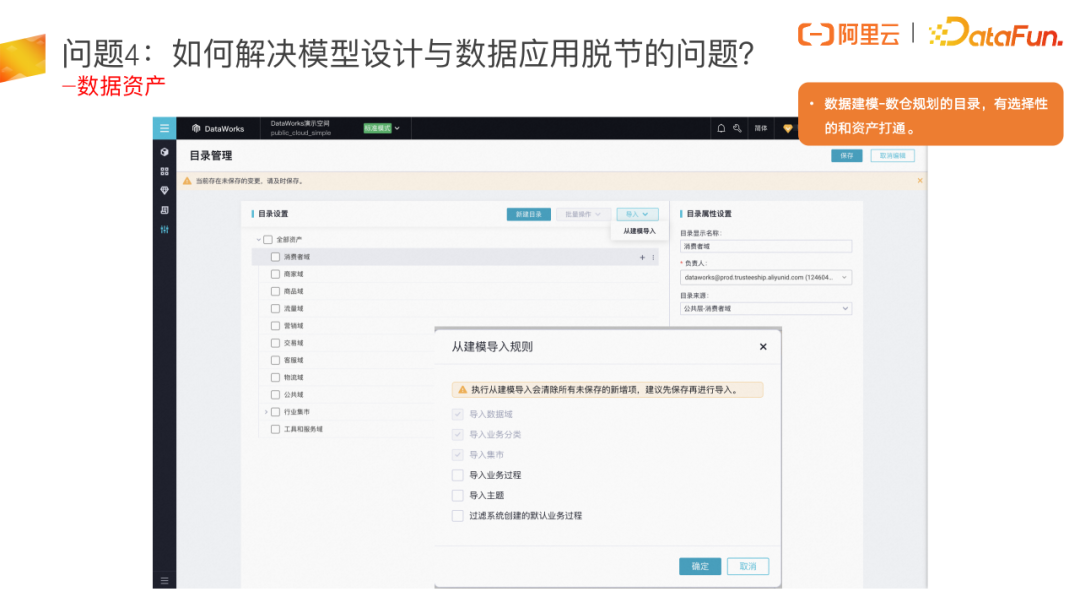
数据模型设计好之后,一般都是用于给大家去使用的,我们一般会将稳定下来的模型在资产中进行上架操作,这样模型就可以被大家找到和消费。数据建模的分层划域可以和资产目录做好映射,打通之后模型可以自动上架到数据资产以被找到和消费。
04 数据模型应用-数据资产介绍
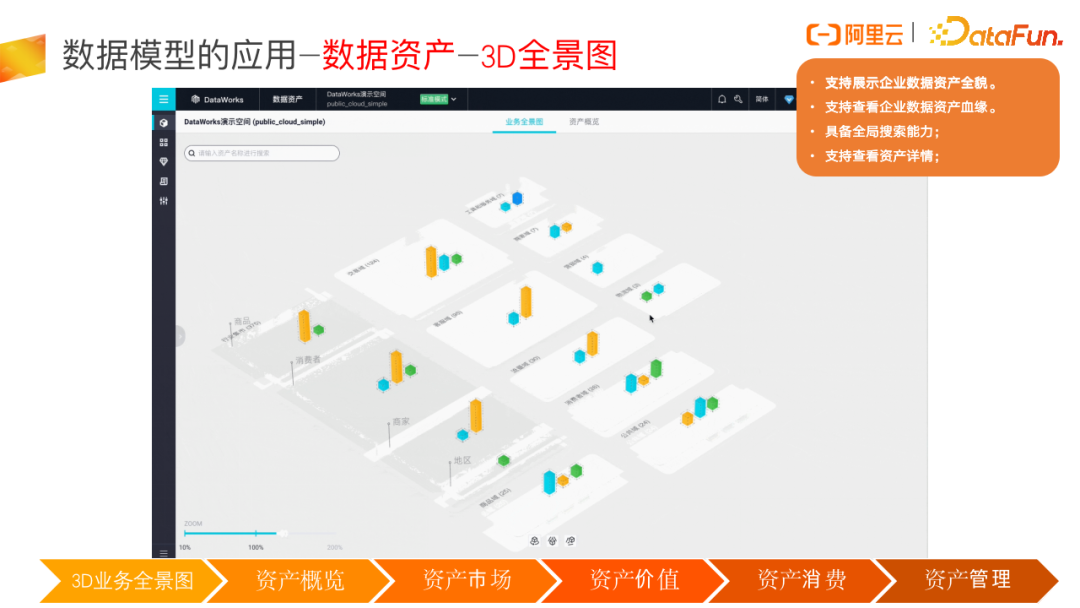
DataWorks 数据资产 3D 全景图,旨在展示企业数据资产的全貌,让数仓同学的工作能够显性化体现出来并且能体现出业务价值。
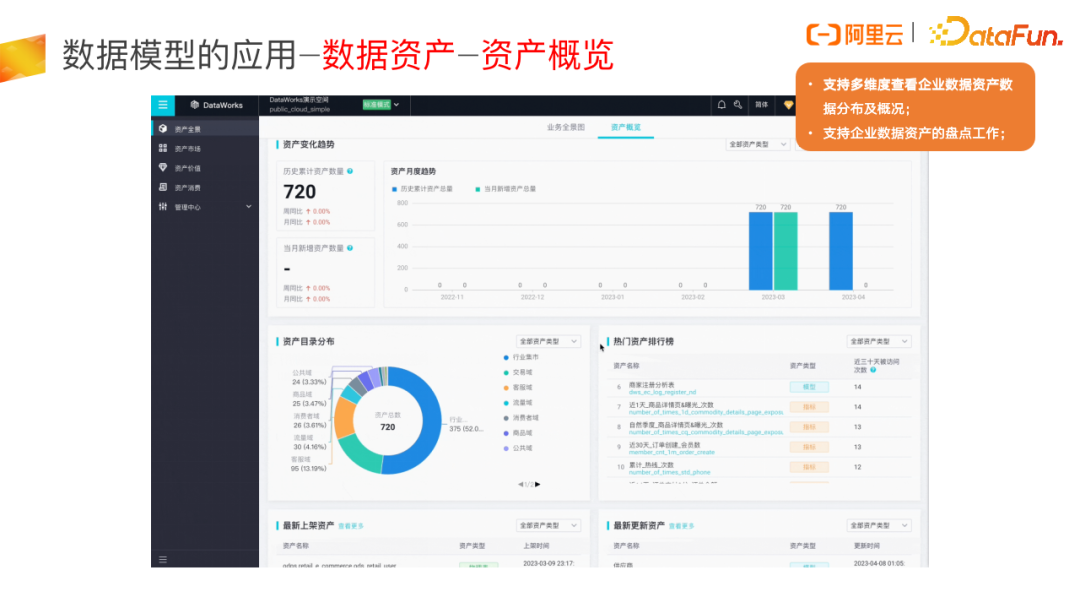
资产概览是一些比较常规的统计性的信息,资产管理员可以在这里从不同维度来观察企业数据资产的分布情况,便于做好企业数据资产盘点工作。
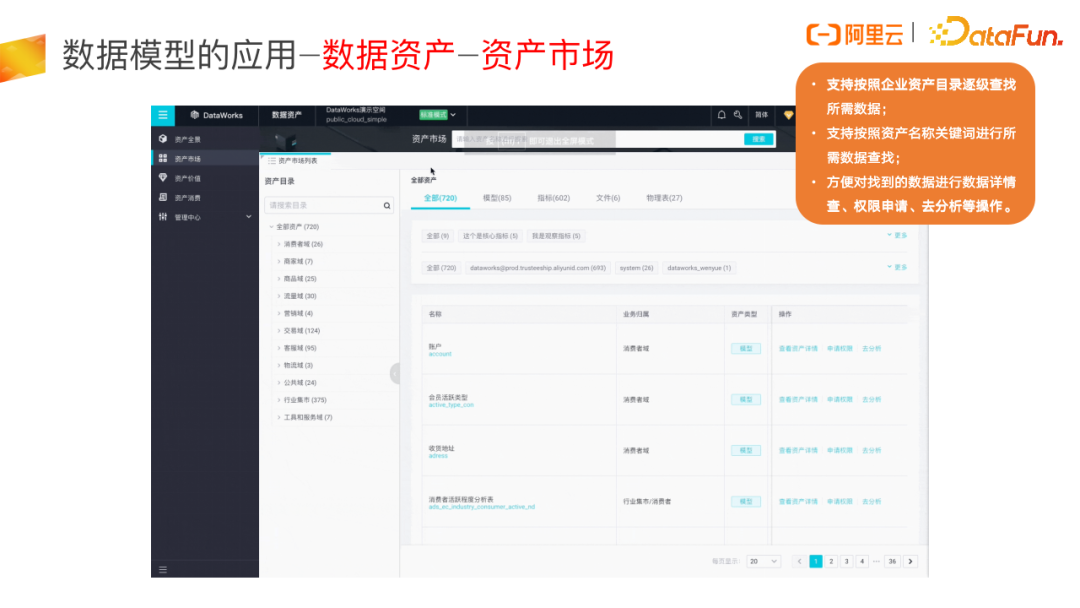
资产市场更加适合于业务人员日常去找数据资产及用资产,管理员可以将希望开放给业务人员的数据资产进行上架。
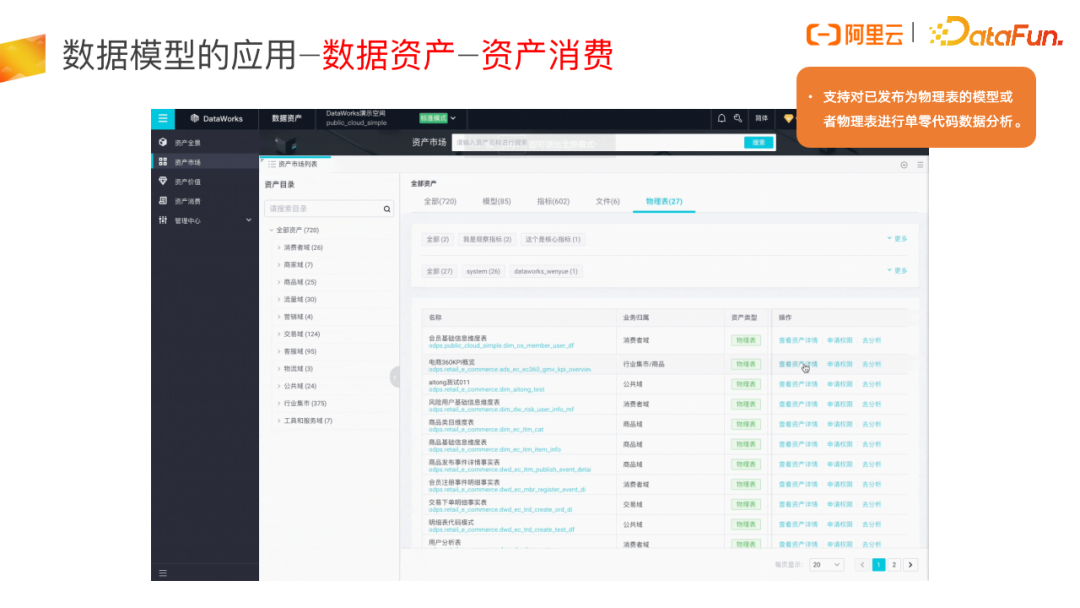
最后讲一下模型的应用,模型一旦物化之后,在数据资产上也可以直接去做字段的勾选以及 SQL 分析,完全是零代码,当然只是单表建模单表分析,结束后就可以直接下载数据。
05 Q & A
问:DataWorks 是否支持拉链表?
答:拉链的自动生成,现在还没有对外开放。
问:数据资产是怎么分享的?
答: 我们是由管理员开放所需共享的资产,放在数据资产模块里。普通业务人员间的资产分享,现在还是通过直接发产品地址的方式。
DataWorks 智能数据建模目前已经在阿里云上商业化,当前推出个人版本,6个月仅需60元,并赠送零售电子商务模板和学习教程供各位开发者使用。
以上就是本次分享的内容,谢谢大家。
分享嘉宾INTRODUCTION
爱桐
Dataworks 产品专家
阿里巴巴集团
阿里云 DataWorks 产品专家,主要负责数据建模、数据资产及数据分析等产品工作。阿里巴巴9年数据产品工作,曾先后在安全部及天猫精灵从事数据产品工作。
文章来源:“DataFunSummit”微信公众号