

导读 本文将从工程的角度,分享快手图数据库存算分离架构及其在实时推荐召回的应用。主要内容包括以下四大部分:
1. 应用场景
2. 核心诉求
3. 存算分离架构
4. 性能要点
01 应⽤场景
1. 三角问题-扩散
首先来看一个图推荐中经常会遇到的场景,图扩散。
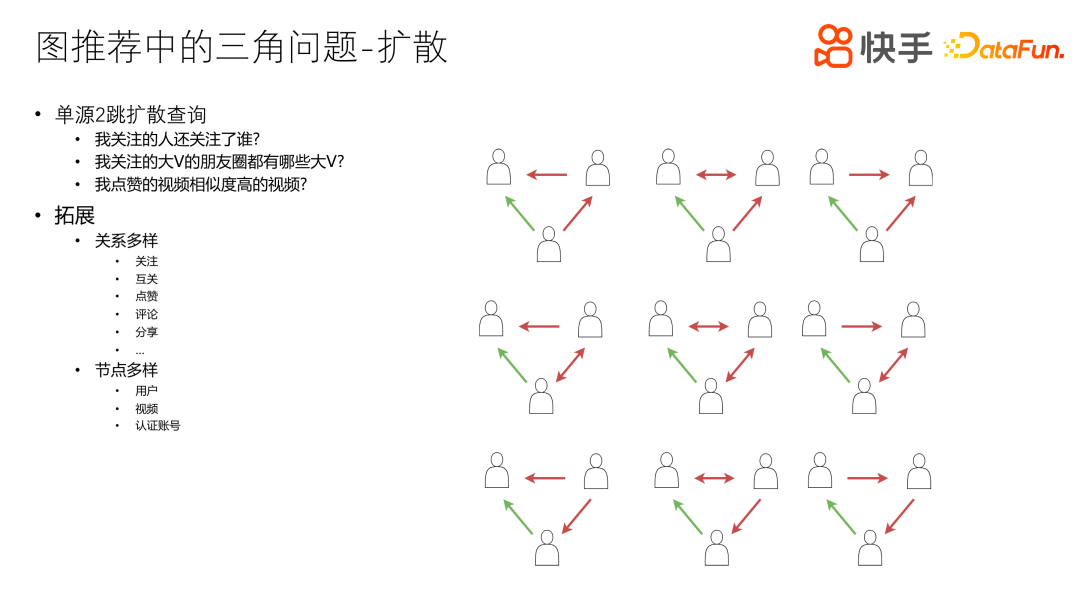
如上图所示,已知一个点,由此点出发,找自己的行为关系,到达一个中间结点,再到另外一个结点,这样就是两跳。两跳之后获取全部数据,然后进行内容的推荐计算,比如我关注的人还关注谁、我关注的大 V 的朋友圈有哪些大 V、我点赞的视频相似度高的视频有哪些。其中朋友圈有很多定义方式,比如他们的互关、交互程度即亲密分数比较高、互动比较频繁,或者其它一些定义。
这种场景的特点是所见即所得。对简单规则推荐的业务场景来说,用语法上线速度是非常快的。
对于其他拓展场景,关系可以是多样化的,比如关注、互关、点赞、评论、分享,还有一些其它的关系比如 Facebook 好友等等。另一方面,节点也可以是多样的,包括用户、视频以及认证账号。
这种推荐方式非常常见,可以取得很好的定向推荐效果。

这种推荐方式可以用 Cypher 语法来描述,如上图所示,从一个点出发,经过一个边,再经过一个边,最终拿到一个点,对这个点来计数。当然这个计数只是一种方式,还有其它一些方法比如 sum(sim_score),计算出最终的 score 值,根据 score 值排序、截断,然后推荐。正常情况下,推荐的结果一般不会超过一千,但是中间访问到d的数据量是很大的,突破几十万都是很正常的。快手这边 Follow 上线目前是五千,其它边可以轻松达到几十万、上百万的数据量。
2. 三角问题-共同
再来看第二个场景,共同关注。
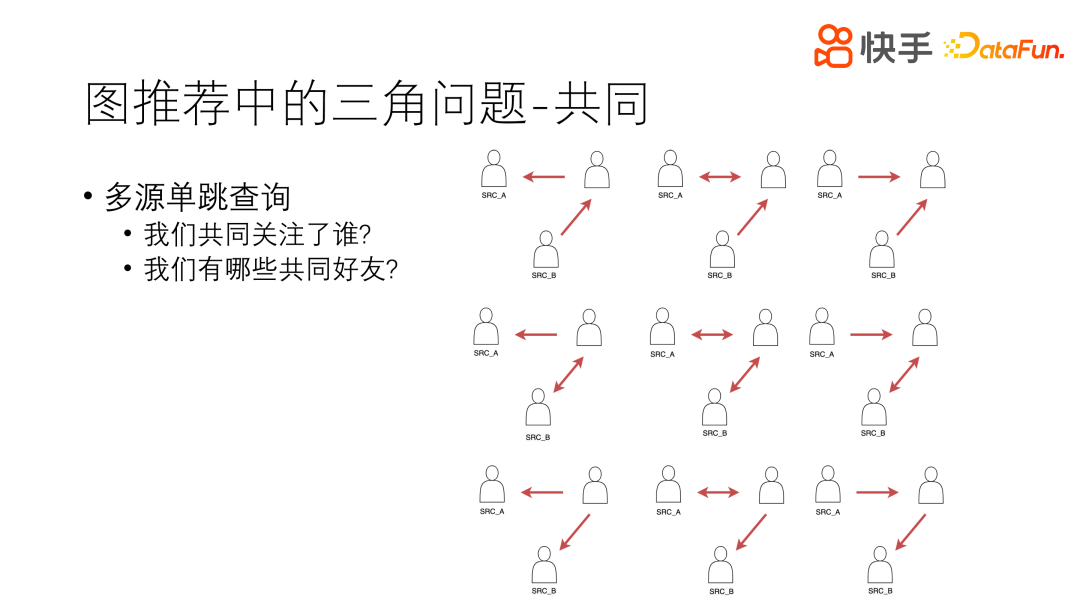
已知两个点,来确定他们之间是不是存在一些关系,比如共同关注的关系、有共同的好友或是有共同的圈子。主要应用场景是,点开一个陌生的头像或是陌生的主页,为了诱使用户与其发生更进一步的关系,就会告诉他我们有共同的兴趣爱好,这属于点对点的推荐方式。

为了解决这样的问题,采用共同类的方式,具体方法是分别从这两个点出发,最终拿到一个目标,共同的一个点,进行聚合 UNION ALL,得到一个聚合后的 COUNT 值。
为什么要用聚合的方式而不是用其他方式?我们在访问过程中,会有很多的筛选条件,比如要求过滤掉大 V 帐号、过滤掉已经封禁的帐号等等,筛选条件会比较丰富,可能还要根据最终节点拿到他的属性进行筛选,这样每两个跳都可以单独筛选,最终拿到这样的结果。
3. 存在问题
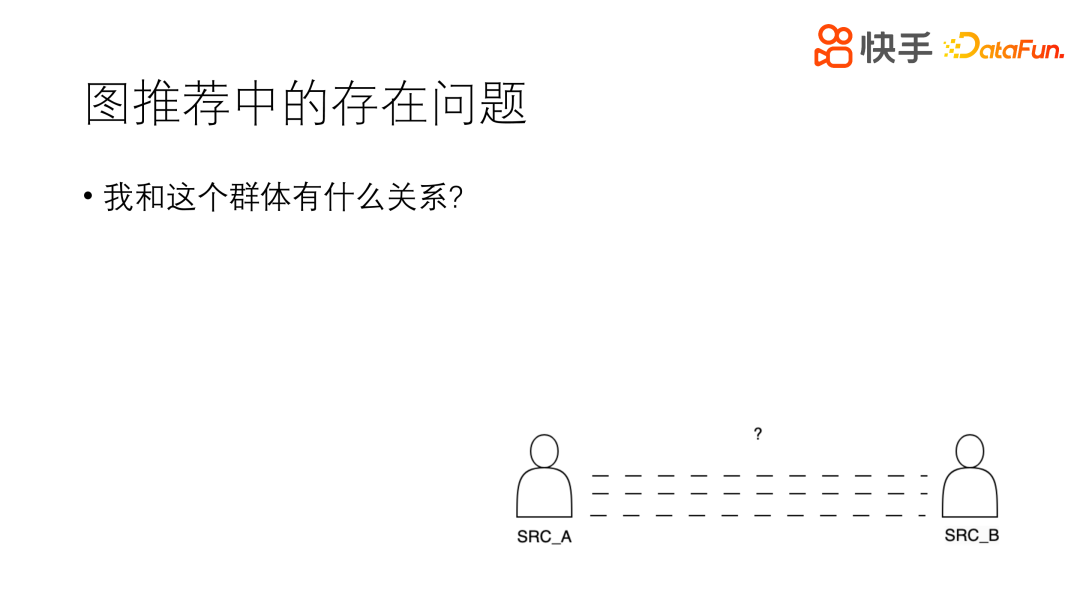
存在问题,指的是我和群体有什么关系。比如博主发了一个视频,评论列表中有几十万,不可能每个评论都回复,这时就需要推荐出一些有价值的评论,进行回复,可能需要判断他们是不是朋友、是不是亲密度比较高,这样可以打上一些标签,博主就更可能会和其进行一些互动。

对于这类需求,我们采用了内置的图算法,看是否存在一个这样的边,如果存在一个这样的边,就返回一个 ‘Follow’、‘FollowBy’、‘Friend’、‘Like’ 等关系,这些关系是根据用户的使用场景具体定义的,最终对边进行标签化的展示。
02 核心诉求
前文中讲到了三种场景,更多的情况是这三种场景的糅合,会比较复杂。用户的核心诉求为以下三点:
- 成本:数据量超过千万级别,多种不同的边,总数据量可达到万亿级别,几百台机器满足简单的需求是不可接受的,因此成本是备受关注的一个点。
- 性能
- 易用
以上三点缺一不可。
03 存算分离架构
1. 整体架构
存算分离架构是近年来数据库领域非常火热的一个架构,其主要特点就是按需部署。CPU、Memory 和 Disk 是相互隔离开的,每一部分都可以单独扩容。这样就可以很方便地找到瓶颈所在,并单独对其进行扩容,从而降低成本。
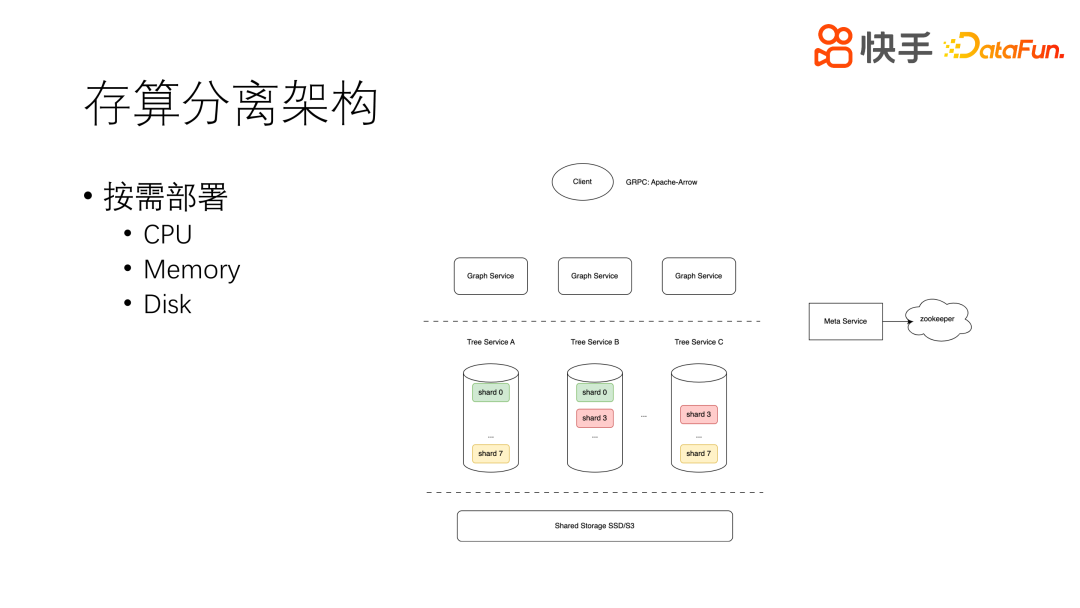
快手当前的架构主要是分为 Graph Service 层、Tree Service 层和 Storage 层。
Graph Service 层就是语法的执行层。
Tree Service 层是图的模型层,中间会有 Cache,主要提供 Memory 选项。
Storage 层是由 SSD 磁盘存储和 S3 冷存储多样存储组成,这一层进行了冷热分离。
正常的情况下,我们的成本主要集中在内存层,因为我们的图对内存的需要比较高。
2. BWTree Service
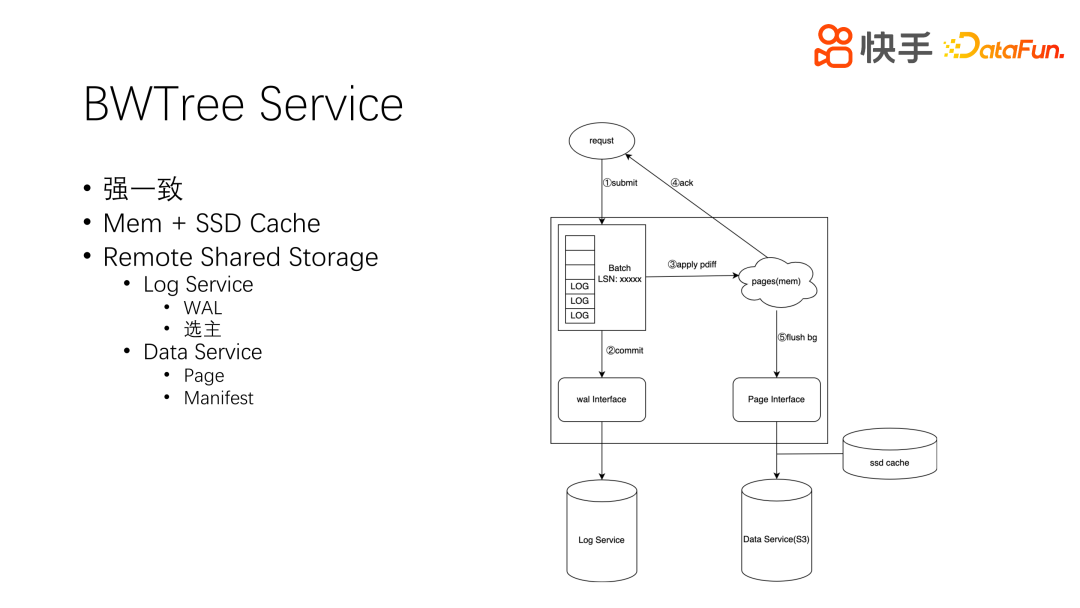
BWTree Service 是内存层,是图描述的一层,对其最主要的诉求就是强一致。因为图的模型有一些其他衍生出来的数据结构,比如唯一性索引,物化出来的 num neighbors、双关等,如果不能做到强一致,整个模型会存在一些问题。它主要是利用 Mem 和 SSD 作为 Cache。
先来看一下用户请求的处理过程,如上图中右侧所示。用户发起一个请求,加入到请求队列,用户所有请求都在一个队列中。Tree-writer 线程工作中,会把这些请求打包成一个 Log,commit 到 WAL-service,这是强一致性存储的一个外部存储平台。commit 成功就可以应用 Wal-diff 到内存中;如果 commit 冲突,即 WAL-service 已经有了这个 Log,就要把最新的 Log 拉回来应用到内存,再重新执行上述过程。这样就可以保证强一致。最后就是 Log 应用到内存中,并返回成功。这里的 flush 后台线程,执行的频率比较低,大概是几十分钟至一个小时才会把所有的数据 flush 一遍,速率取决于当前的脏页率,尽量降低对持久化存储的影响。Page 持久化存储会分为两层,一层是 SSD Cache,还有一层是 S3 存储,可以进一步降低成本。我们的 Wal-service 除了刚才提到的日志,还兼具选主的功能,即多副本的情况下进行选主。
3. 紧凑内存模型
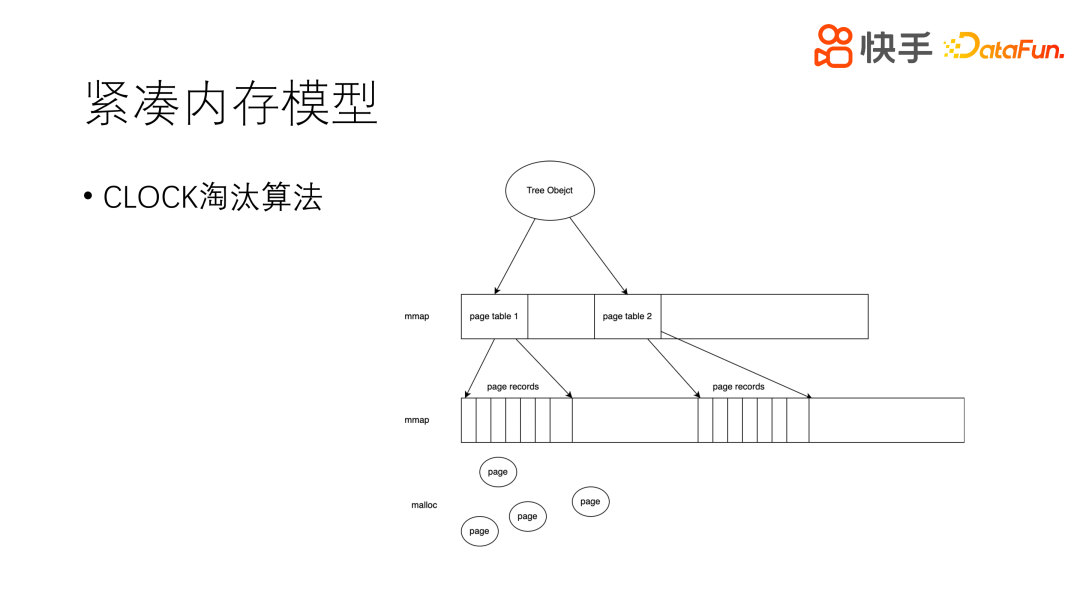
前文中提到,内存是成本的主要来源。我们的内存模型和操作系统是比较相似的。用 mmap 申请很大的三块内存,分别作为一/二/三级页表,和操作系统的页表是同一个概念,在紧凑的内存空间是没有任何浪费的。第三级页表,指向真实的数据。数据是用 malloc,因为我们希望页本身是可变大小的。实例内存比较满,就进行淘汰,从 page records 左侧开始遍历,遇到 access_num 为 0 的页就可以淘汰,这个过程也和操作系统比较像,因此我们也是用的 CLOCK 淘汰算法。
4. 边模型
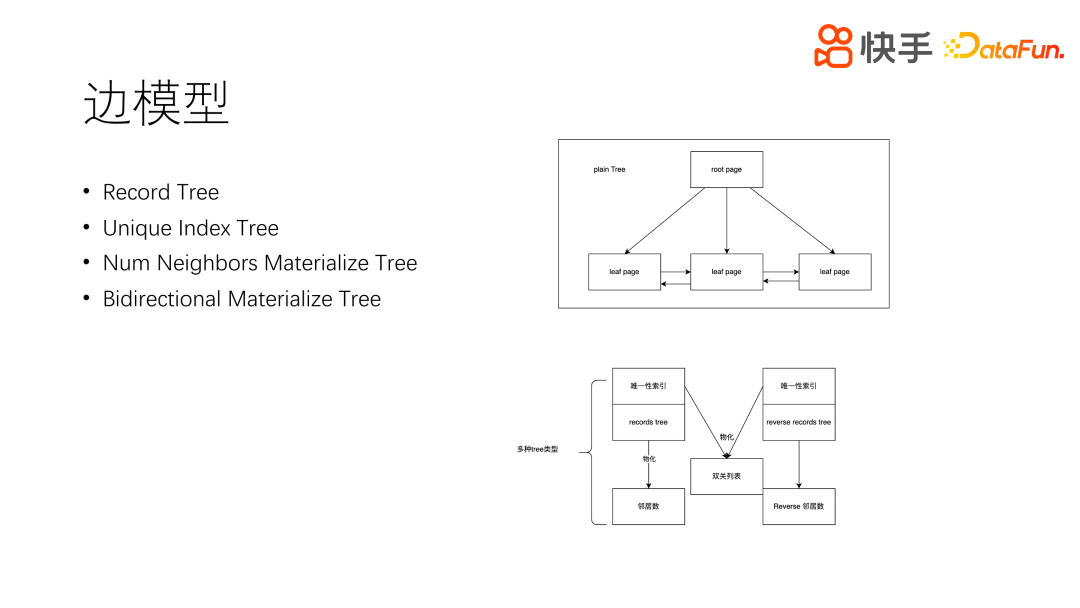
前面讲解了树模型,但是树模型不能完整地描述边,边有四种树结构,分别是 Record Tree、Unique Index Tree、Num Neighbors Materialize Tree 和 Bidirectional Materialize Tree。Record Tree 是记录树,Unique Index Tree 是索引树,关系链树是需要维护索引的。Num Neighbors Materialize Tree 是邻居的物化视图,主要记录在一点有多少个邻居,有多少个评论树,多少个好友树。物化视图的更新主要是依据普通的树更新,根据主树来更新。Bidirectional Materialize Tree 是双关物化视图,根据出边和入边物化出一个双关列表。以上四种树可以根据用户配置来进行生成或不生成。
5. Snapshot 隔离性
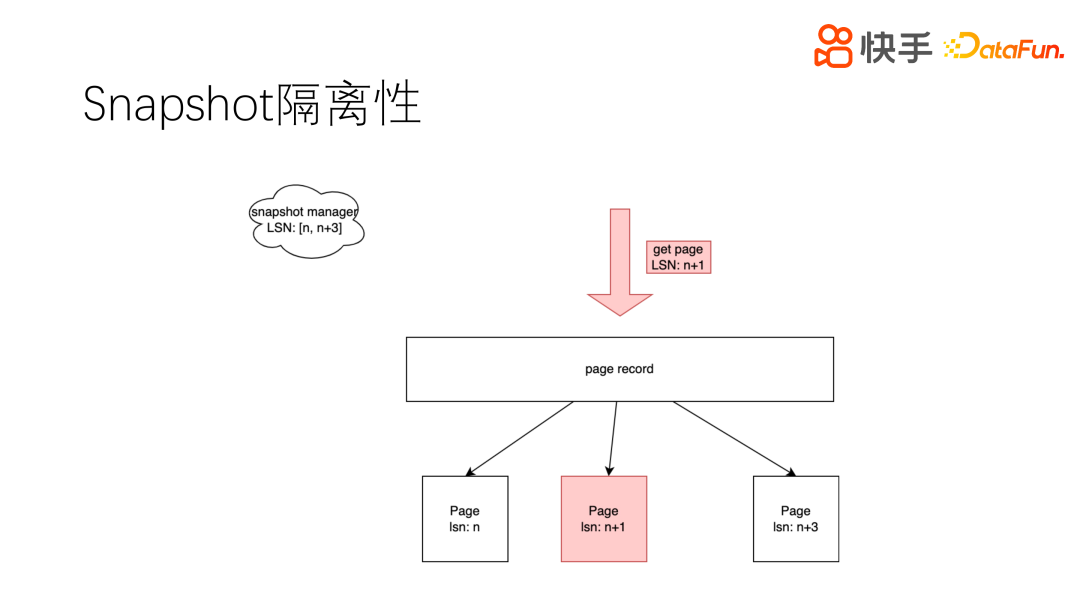
在实时读写情况下。需要做到读视图 snapshot 一致性,不能出现幻读和未提交读。每个页有多个版本,修改页则复制一份页数据,并产生新的版本号,多个版本的页都记录在 page record 中。访问请求携带一个版本号 n+1,就可以区分并访问期望的页,从而实现了隔离。
04 性能要点
1. Share Nothing
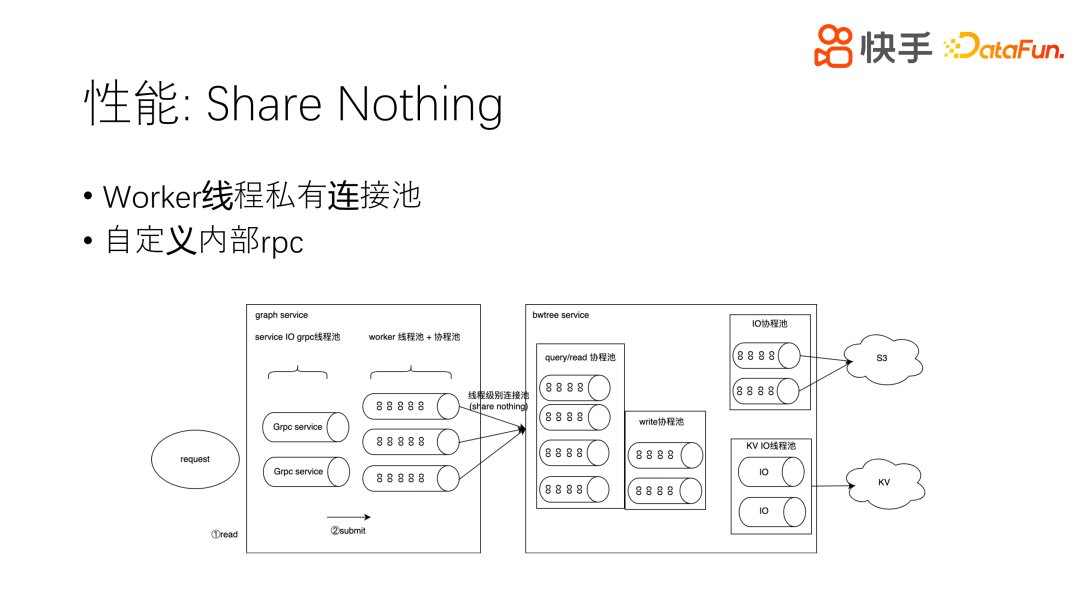
比如一个两跳查询,一跳是 500,最终需要拉取 25 万数据。假如每跳是 5000,那么最终访问的数据就会有 2500 万。当然,2500 万数据的访问量级在实际使用中是不会出现的,我们都会进行限制,但即使限制到几十万的数据,对于经典的数据库也很难做到百毫秒以内返回,我们现在可以做到十万数据的查询计算 10 毫秒量级返回。性能是比较好的。那么我们是如何做到这样的性能的呢?
比较重要的做 Share Nothing,这是数据库中一个比较经典的概念。用户的一个请求到了一个线程,这个线程有个协程,协程在发起请求的情况下使用线程绑定的连接池发起,不用再跨线程。因为跨线程是很耗时的,即使什么也不做也要时延大概 0.08 毫秒,如果多次跨线程总时延会达到 0.4 毫秒,对于线上的一些核心产品应用来说,和 Redis 对比,0.4 毫秒已经是比较高的延时了。Share Nothing 要求连接和本线程进行绑定,和 Tree Service 特定 worker 线程绑定,同样,在收到请求的情况下,也是在本线程执行,主要是读的过程,如果要发起到 S3 冷存储查询请求,或 KV 磁盘存储查询请求也都是在本线程。这就是 Share Nothing 的概念,尽量不要跨线程,数据也是在本线程完成的。
2. 数据流
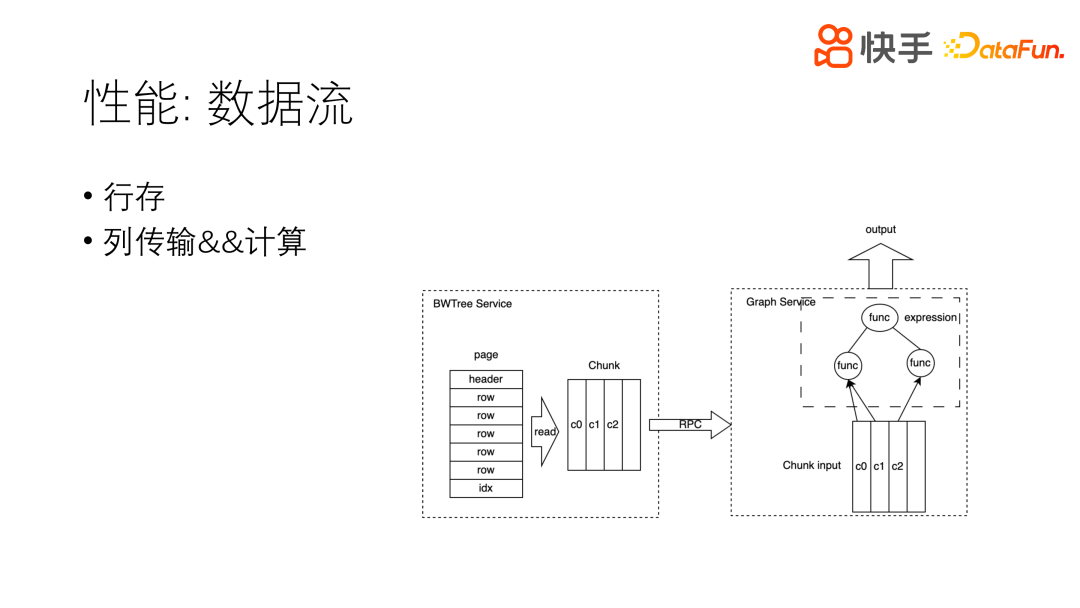
以上介绍了数据请求的过程,接下来看一下数据回传的过程。数据最终的叶子节点,存储格式是行存,但是在读之后就成为了列存格式。因为行存在更新时性能会比较好,列存时实时更新性能极差。因此,我们做了取舍,存储时用行存,读出之后所有数据用列存。读出之后的列存数据格式,在经过 RPC 时,压缩效率和传输效率等都会比较高。最终到 Graph 层,数据经过一个个算子表达式。列存数据作为算子的输入,可以做向量化的运算。最终拿到的输出也是列式进行输出,我们用的是 Apache-Arrow 数据存储格式返回给用户,也是列式存储。因此,这样的架构特别适合图地查询和计算。
李本利
快手 图数据库工程师
在滴滴,腾讯,快手从事多年数据库研发工作。近年来专注于图数据库内核研发,追求强一致,低成本,高性能,致力于满足用户更多使用场景。
文章来源:“DataFunTalk”微信公众号