
导读 本文将分享爱奇艺埋点体系的演进过程。
本次分享将涵盖以下五个方面:
1. 埋点对于数据的重要性
2. 爱奇艺埋点体系的演进
3. 主要的投递时机和事件
4. 数据的后续加工处理
5. 正在做的改进
01埋点对数据的重要性
首先来介绍一下埋点的概念和意义。
1. 什么是埋点
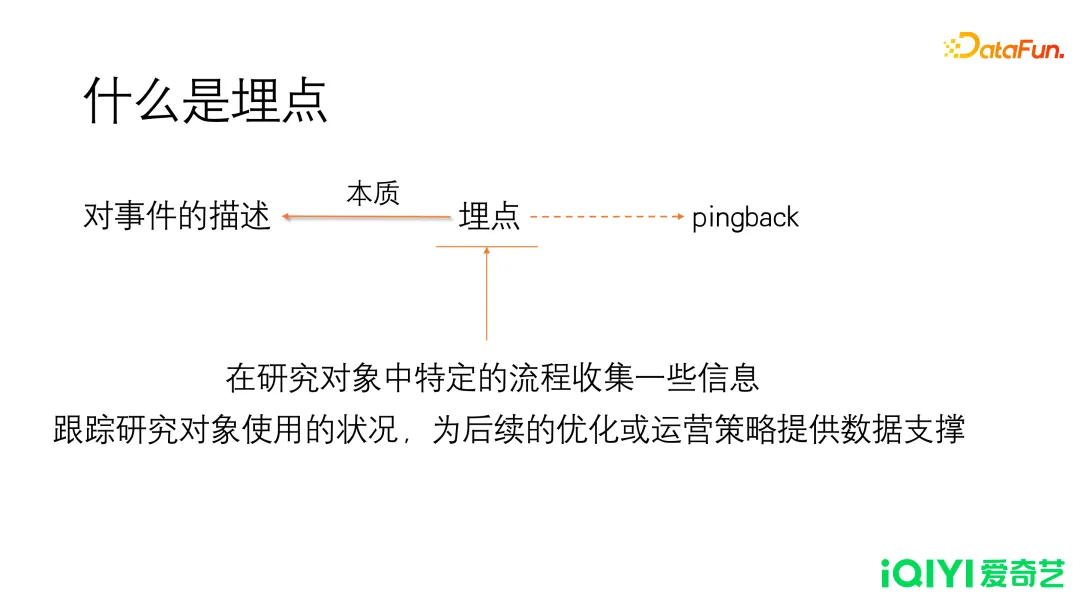
埋点本质上就是对事件的描述。举个例子,比如要研究一位员工的通勤情况,我们不需要每天跟踪去拍一个视频,时刻记录。虽然视频包含的信息很丰富,但是对于我们研究的通勤情况,存在大量的冗余信息,另一方面,视频信息并不是结构化的,非结构化的数据会给之后的分析带来困难。以数据埋点的思路,解决方案是:在员工位置或者状态发生变化的时刻,记录当时的信息。比如在他走出小区,到达公交站,上车下车、换乘,最后到达公司,这几个关键节点进行记录,就可以获知这位员工的通勤情况。
埋点的要素
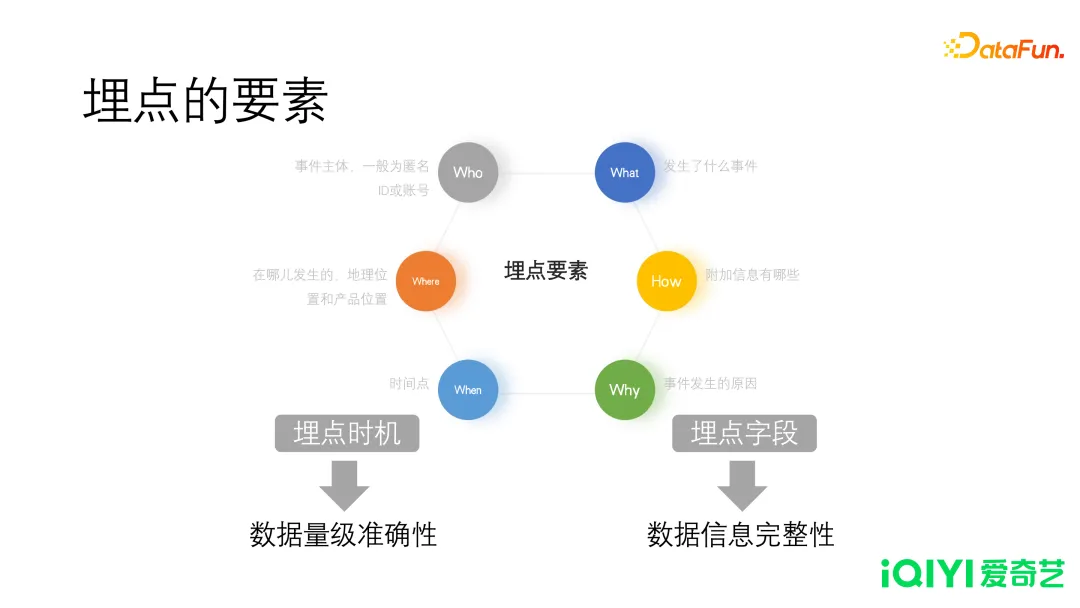
埋点的要素,从中文的语法上讲,即谁是什么,或者谁做了什么。包含两方面,时机和信息。
- 埋点时机:时机,是指触发埋点的条件。回到前面的例子,员工发生关键行为的时刻或者状态,比如出门,到车站,换乘,最后到公司,都是关键位置,此时就需要进行信息收集。时机的准确,体现在数据量的准确性,行为是否连贯,时机不准确表现为漏投或者多投,如果我们丢失上车这个时机的埋点,就无法获知用户上车的确切时间。
- 埋点字段:在上述例子中,天气状况、交通工具的耗时、换乘方案,都可能是研究的重点。相对而言,公交车的车牌号,或者车上是否有座位,就不属于关键信息。信息的完整性体现了数据的价值。
2. 埋点的意义

埋点是数据的基础,埋点产生数据,数据最终影响运营和决策。
- 报表:用于统计分析,计算活跃、留存,衡量增长、运营的质量。
- 用户画像:根据用户的行为,构建用户画像,体现在特征和标签的准确性。
- 推荐:分析用户偏好,归纳行为特征,从而实现用户个性化推荐,最终实现在用户时长。用户时长增加,会产生更多的数据,形成闭环。
02
爱奇艺埋点体系的演进
爱奇艺埋点体系的发展经历了五个阶段。
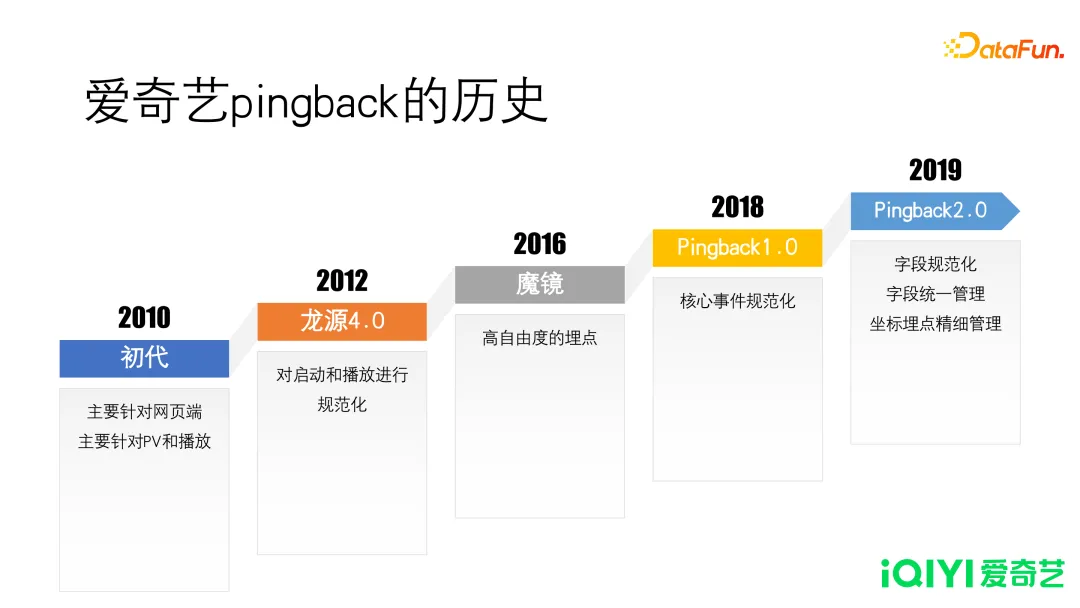
- 初代(2010):网页端的PV 和播放
- 龙源 4.0(2012):启动和播放的规范化
- 魔镜(2016):高自由度埋点
- Pingback1.0(2018):核心事件规范化
- Pingback2.0(2019):字段规范、统一,坐标精细化
1. 魔镜自助阶段
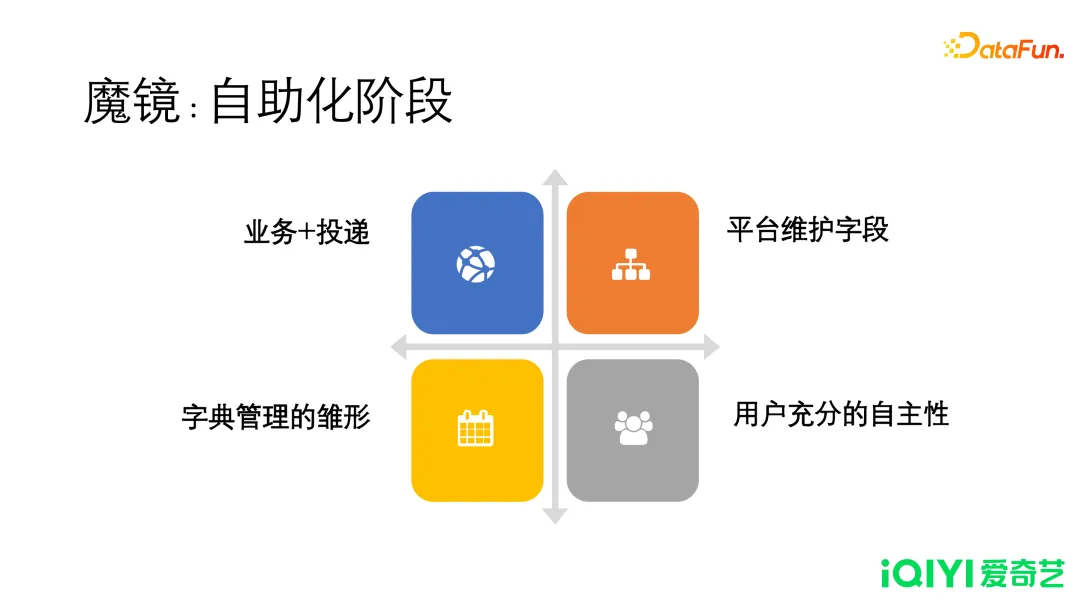
魔镜具有如下一些优势:
- 以业务和投递的粒度管理,每个投递是一张独立的物理表。
- 平台维护字段:常用的核心字段,如设备 ID、频道、时间戳等关键字段,抽离出来放在公共字段里面,其他业务字段放进一个 map 结构。
- 用户充分自主性:用户自行维护投递的时机和字段定义。
- 字段管理的雏形,给每一个字段关联一个取值的集合,取值集合可以提供给其他数据平台。在统计分析中,可以关联出一些中文值,提升报表的可读性。
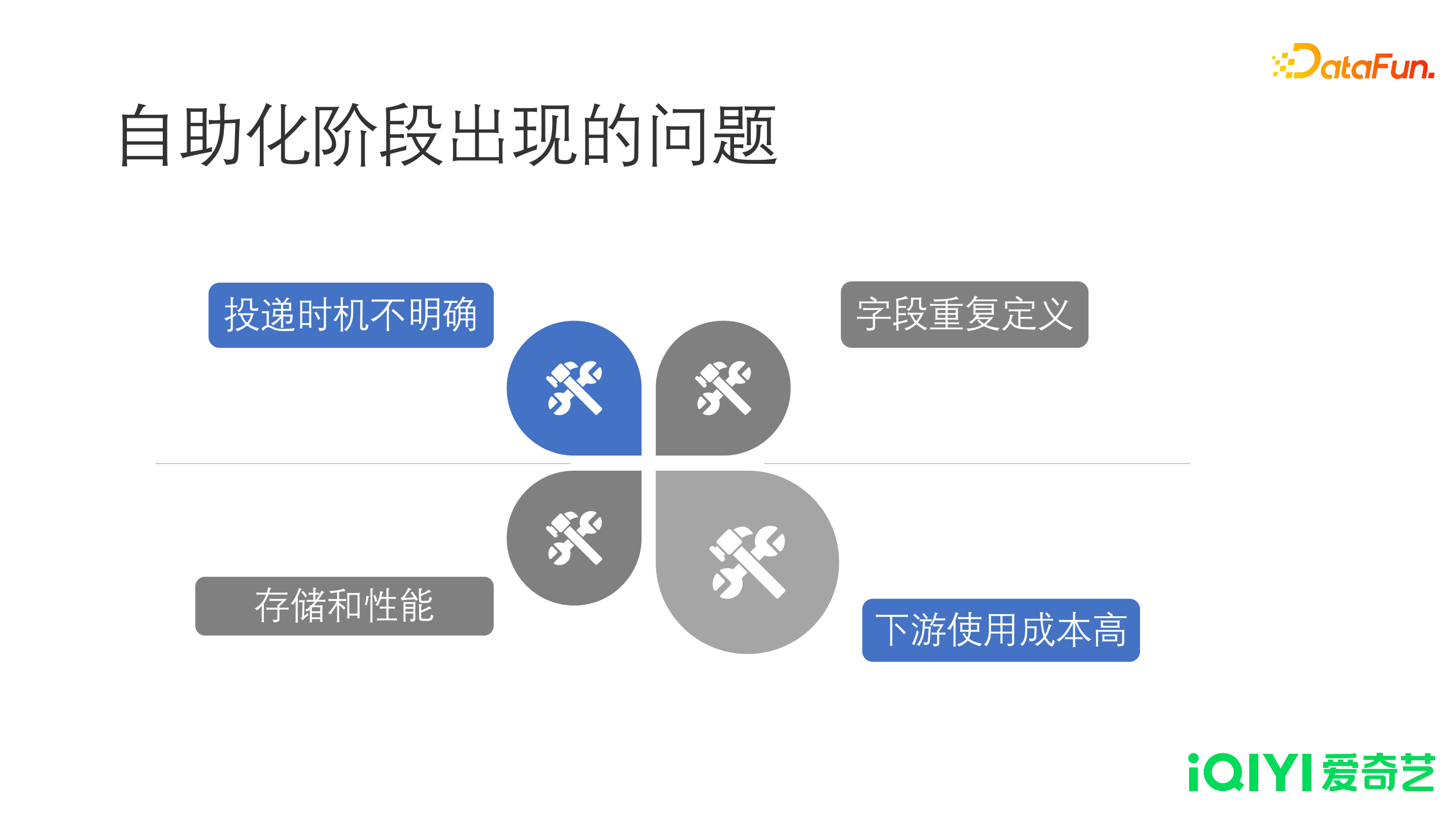
随着自助化阶段的发展,魔镜出现了一些问题:
- 投递时机不规范不明确:因为定义的投递,在平台中是一个中文名称,不包含任何时机方面的含义。投递之间,对于时机的定义,存在交叉和模糊。相关信息通过文档或者口口相传,经过一段时间,最终表现为无法复用,数据冗余。
- 字段重复定义:因为时机的不明确,缺乏通盘考虑。很多字段在投递之间、业务之间,甚至投递内部都有可能被重复定义。因为多个同事维护投递,大家都不敢去在一个陌生的字段里面投递内容,所以每个字段都被重新定义,最终导致大量含义相同的重复字段。
- 下游使用成本高:字段问题也造成了下游使用时,沟通成本非常高。使用一张表首先要明确字段的含义以及投递时机,字段定义不清,对于一些统计分析或者推荐场景非常不友好。对于统计分析和推荐,虽然是复用性很强的业务,但是由于字段的不统一,使得代码无法复用。
- 存储和性能:数据爆炸,hive 物理表的 map 结构的存储与性能难以满足需求。
2. 中台阶段
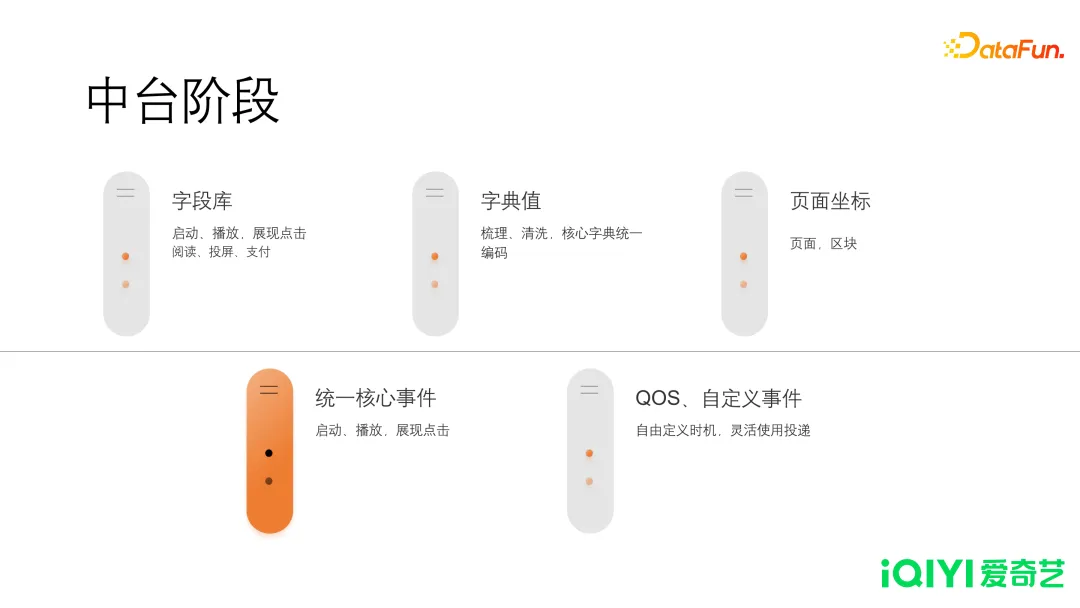
为了解决魔镜自助阶段的问题,需要对埋点体系进行改进,由此进入到了中台阶段。这一阶段在五个方面进行了优化。
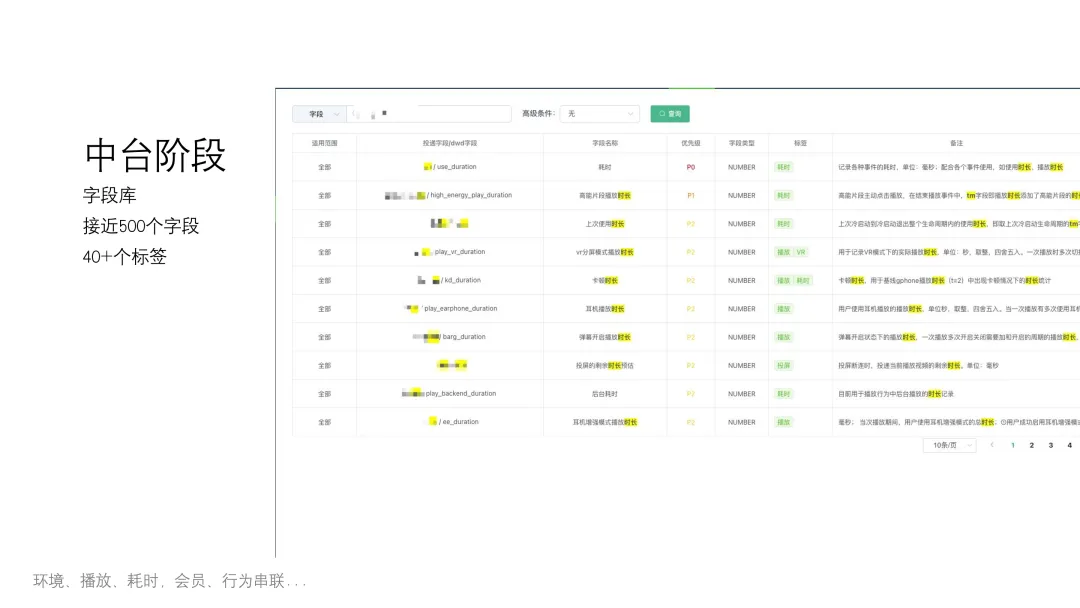
- 字段库规范
- 对已有字段进行规整去重,并按标签分类。
- 字典值梳理
- 核心字段字典强制统一,非核心字段的字典按业务隔离。
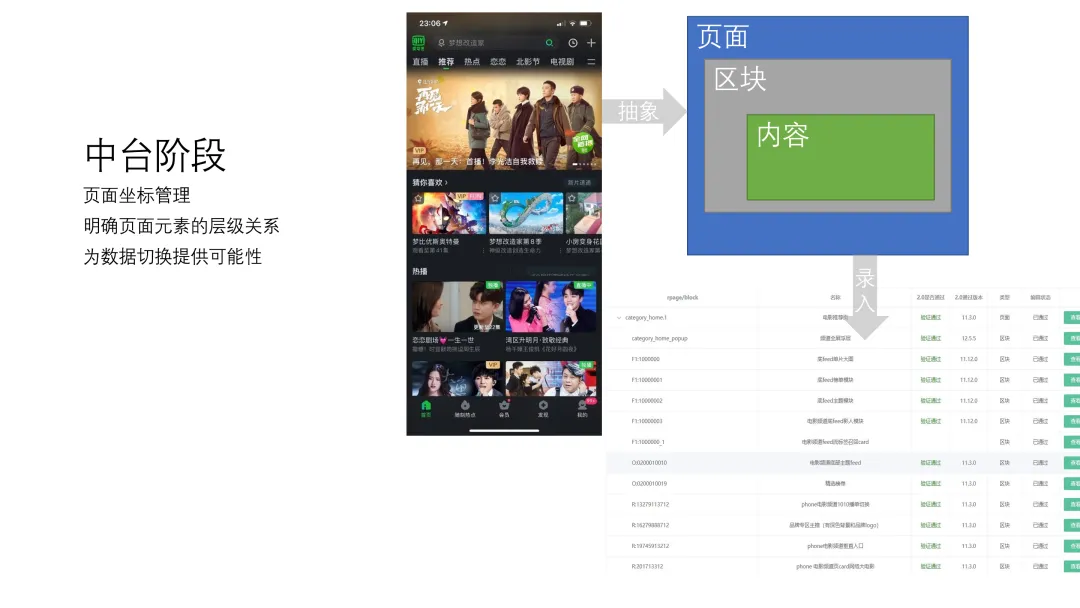
- 页面坐标管理
- 页面和区块,按坐标划分,通过树形结构进行管理。
事件规范
统一核心事件(启动、播放,展现点击),细化事件类型(阅读、投屏、支付、下载)。
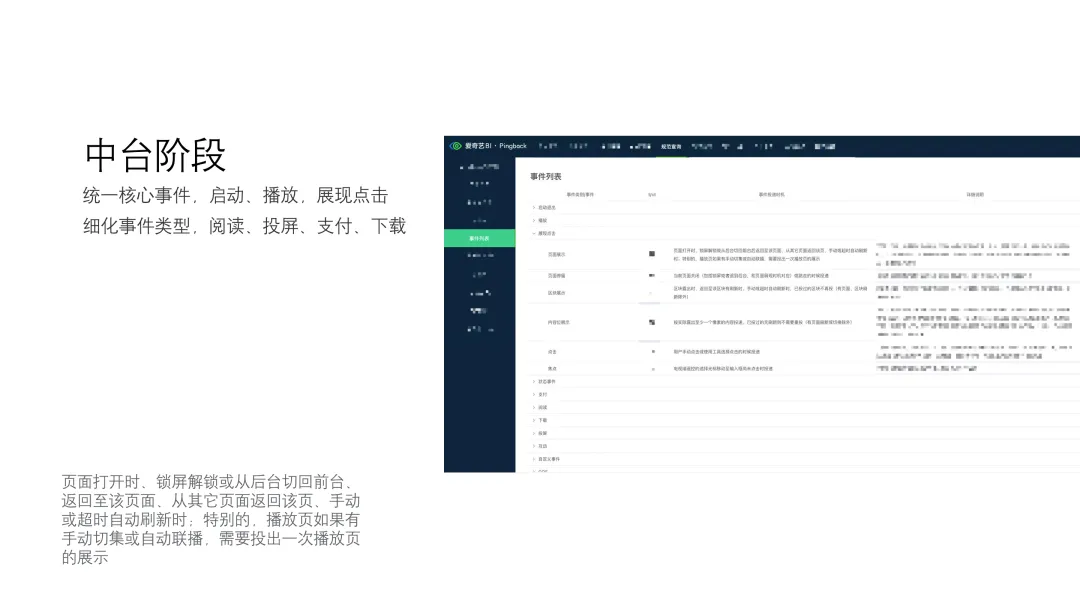
- QOS、自定义事件QOS 主要是帮助技术同学做一些性能方面的统计。自定义事件,还未考虑到的投递,可以由用户根据业务需求自行定义,自行控制。
3. 新旧埋点切换方案
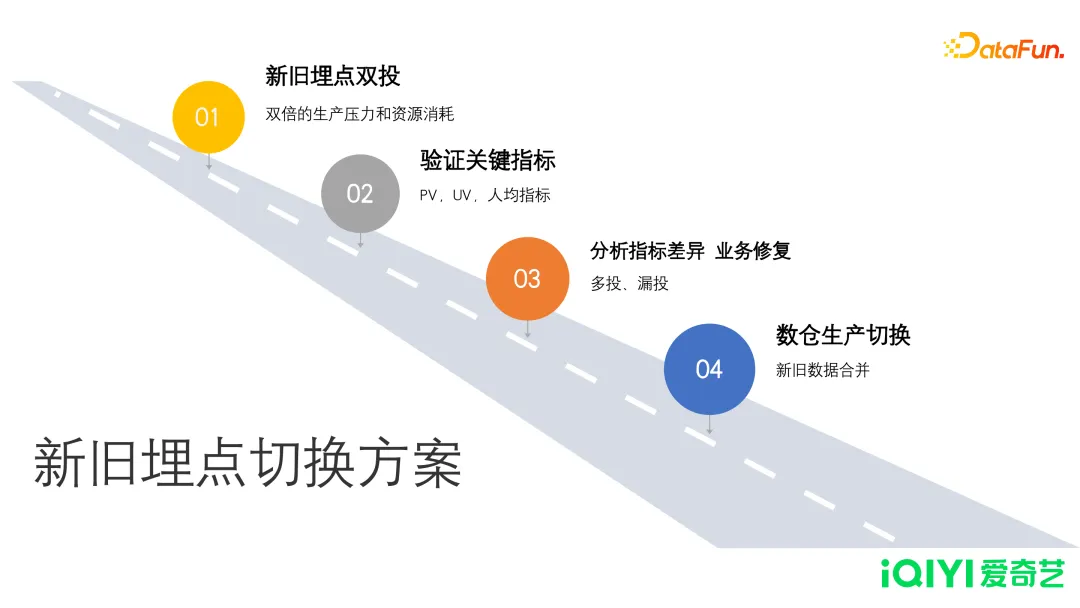
埋点的迭代过程中,投递字段会不断发生变化,一刀切的后果,在业务上会产生很大影响,造成数据无法回溯。为了避免这样的情况发生,需要有一个能够持续推进的方案。爱奇艺的做法是:
- 新旧埋点双投
- 在相应的时机位置,保留旧的代码,同时插入新的投递。这样产生了新旧两份数据。此时数据生产模块面临双倍的生产压力以及资源消耗。
- 验证关键指标
- 在收到两份数据之后,我们会针对这两份数据分别计算关键指标,比如 PV、UV、时长等,来保证新数据是完全能够代替旧数据的。
- 分析指标差异,业务修复
- 如果出现差异,就需要下钻到更细粒度,判断哪个场景导致了这个数据差异,然后反馈给业务去修复。这样可能循环很多次,不断地验证,不断地修复,直到新旧数据能够达到一个比较相近的程度。
- 数仓生产切换
- 验证通过之后,我们以某个版本去切换,小于这个版本号的取旧数据,大于等于这个版本号的则取新数据。做到对下游透明,尽可能避免对核心统计指标的影响。
4. 埋点迭代的阻碍

- 业务切换成本高,代码维护难。因为人员的变动与业务代码迭代,导致不易维护。
- 不能及时看到收益
- 从新老双发、数据验证、数据修复,最后完成切换,最终体现在数据使用上,需要很长时间。数据修复,需要往复很多次,每次修复都需要发版后用户升级或者后端上线,不能及时看到收益。
- 数据验证难度大
- 通常业务上的同事,不具备分析数据差异的能力,所以需要数据部门承担这个任务。数据开发的同事深入了解业务场景,根据数据现象,推测原因,反馈给业务后,推进修复,难度大且消耗时间。
- 长时间的生产数据合并
- 因为是以数据版本来切换新老数据,因此对于一些量小的差异,或者无法查证的数据,要等待其自然消亡。这个时间可能会很长。魔镜阶段已经过去大概 5 年的时间了,到现在依然是有流量的。所以生产数据的合并是一个相当长的过程。
03
主要的投递时机和事件
接下来介绍投递时机和事件。爱奇艺作为视频行业,最重要的两个投递就是启动和播放,相关核心指标是 DAU 和用户播放时长。
1. 启动
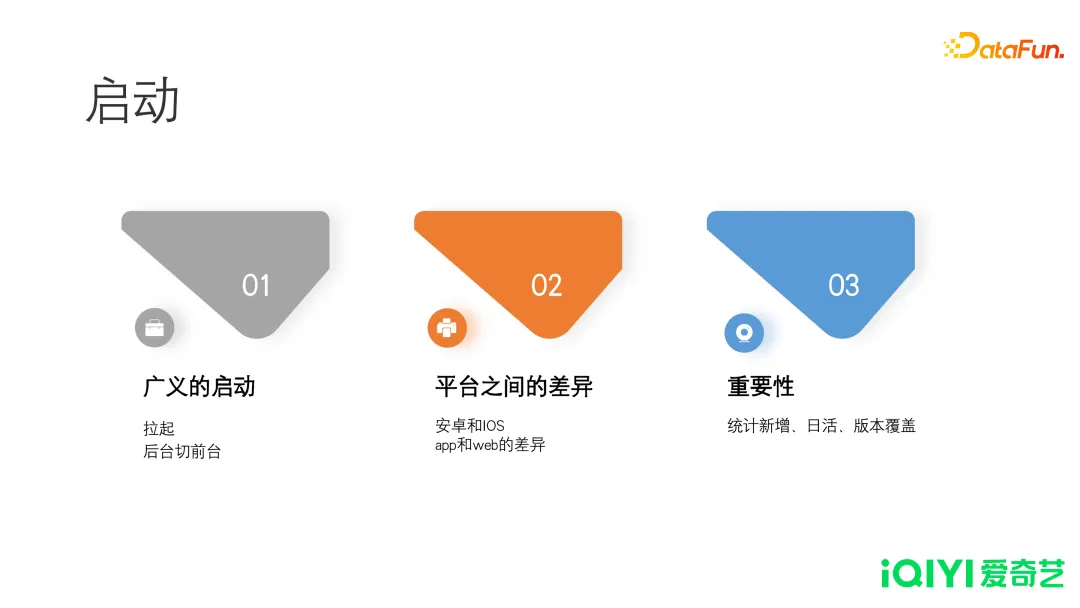
- 广义的启动
- 启动并不仅仅指用户点击图标,触发 APP 的运行。任何第三方的拉起,甚至后台切换到前台,都认为是一个启动。
- 平台之间的差异
- 启动在不同平台之间的差异很大。比如安卓和苹果,切换后台的逻辑是不一样的。安卓是一个真的后台,但是苹果设备可能会被系统杀掉。另一个差异是APP 和网页端的差异。APP 是有明显的启动时机的,需要人为触发才能启动。但对于网页端,用户可以通过任何一个 URL 进入相应页面。在网页端,是没有一个明确的启动时机的,换言之,页面的展示就可以认为是一个网页端的启动。
- 重要性
- 启动计算新增、日活、版本覆盖、新增的归因,都是以启动为出发点的。从业务上,针对启动投递做了多重保障,甚至需要先持久化再投递。这些措施,都是希望启动的数据能够准确获取,可见启动投递是多么重要。
2. 页面展现和点击
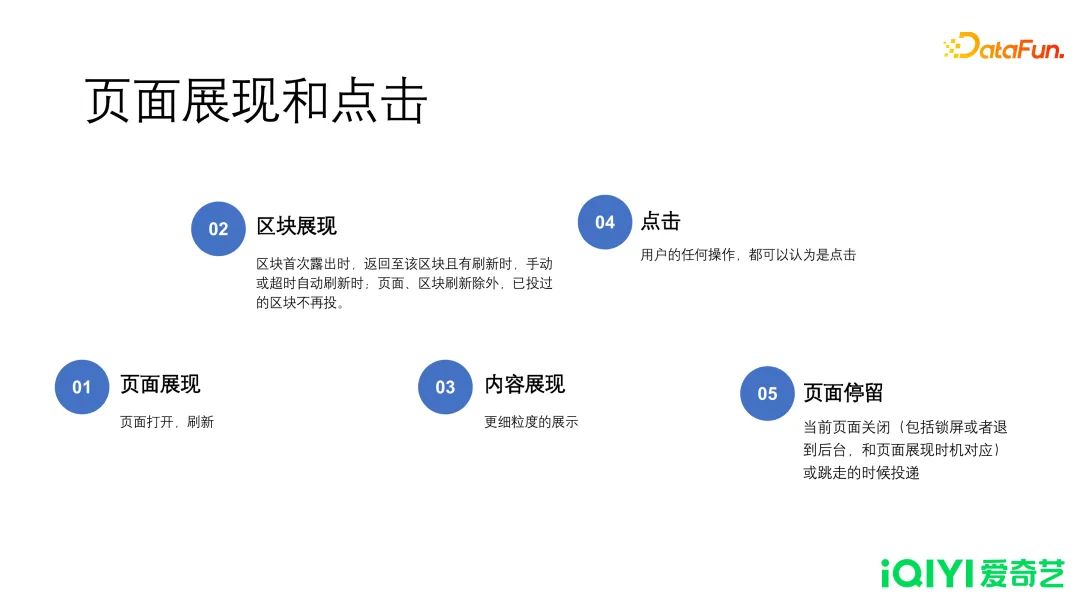
数据量最大的投递是页面类的投递。
- 页面展现
- 即整个页面打开的时候触发这个页面的投递时机。
- 区块展现
- 在一次页面展现中,区块首次露出时、返回至该区块且有刷新时、手动或超时自动刷新时,触发区块投递。
- 内容展现
- 内容展现的投递,是以内容为粒度。只有真实露出并被用户看到,才能触发投递,每个内容都是一条。例如用户在一个瀑布流快速向下滑动,很多内容一闪而过,这部分投递是不需要投出的,需要有一定时间的停留,才触发内容的投递。
- 点击
- 广义的点击,不仅仅是点击一个链接,一个按钮,甚至长按,下拉,上下滑动以及拖动进度条,这些都可以认为是点击,用户的任何操作都可以认为是点击。
- 页面停留
- 当用户以任何方式离开这个页面的时候,触发一条页面停留的投递,主要是为了统计用户在这个页面的停留时长。很多资讯或者新闻类的 APP,也需要关心用户在某个位置停留的时间,以及一些内容露出的情况。
3. 播放
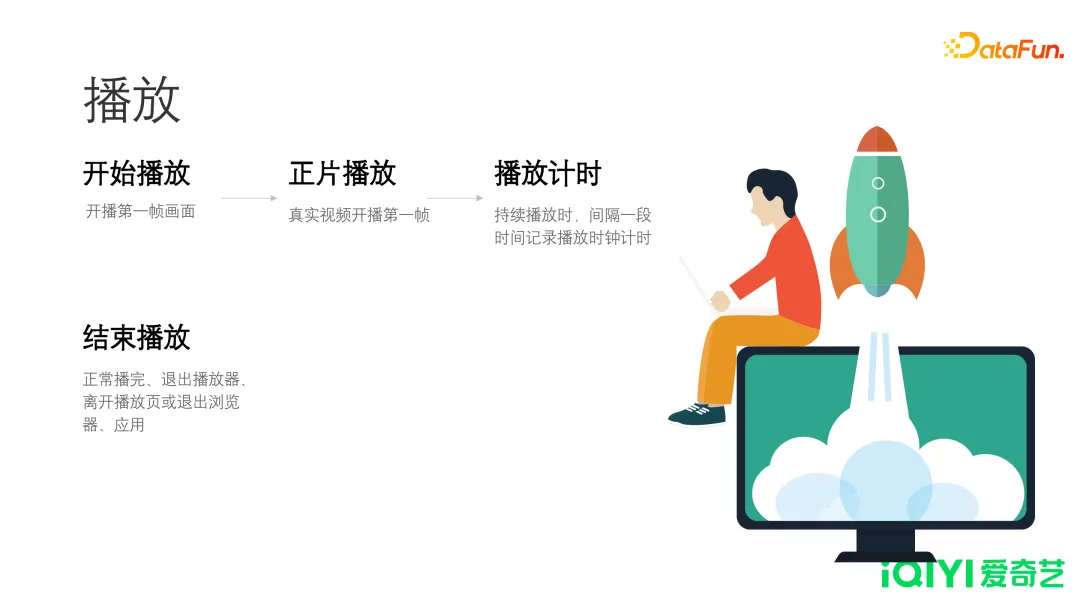
爱奇艺是视频行业,播放投递的重要性是可想而知的。播放的关键信息,包括一个用户在什么时间、从哪儿来、播放了什么内容、播放了多长时间。
- 开始播放
- 指开始播放第一帧画面,可能是一个真实的视频,也可能是一个广告。
- 正片播放
- 即广告播完或者跳过后,真实视频开始播放的第一帧。
- 播放计时
- 在播放的过程中,每隔一定时间,以心跳的方式,把最近的一段时长投出。
- 结束播放
- 任何情况,造成的用户播放停止,都投递结束播放。
04
数据的后续加工处理
1. 质量保障
- 回归测试
- 首先,在测试阶段由测试的同学进行抓包,测试的同学利用自行开发的平台代替市面上开源的抓包工具,通过修改手机 DNS 的方式,让平台获取到数据,最终在页面上滚动显示,以此人为判断投递的质量。
- 灰度指标对比
- 在灰度阶段,通过对比灰度版本与最近线上版本,计算核心指标。由于用户量的差异,导致指标无法直接比较,所以对非均值类的指标进行了折算。
- 上线监控
- 版本上线之后,计算 DAU 的版本分布,来判断一个版本的覆盖情况。当达到一定的覆盖比例之后,会统计核心字段的投递情况。核心字段的投递规则,在取值长度、正则或者数字取值范围,是有明确限制的。根据规则判断其投递情况是否符合预期,以此来计算整个业务的质量分数。
通过以上三个阶段,来保证投递的质量,尽早发现问题,避免后续造成更大影响。
2. 数据湖和实时流

- 实时数据流:主要是 Kafka 流,用于时效、吞吐高要求场景。
- 数据湖:非核心的投递,直接入湖。
- 离线数据生产:传统离线生产数据,从 ODS 生产到 DWD。
3. 数仓生产
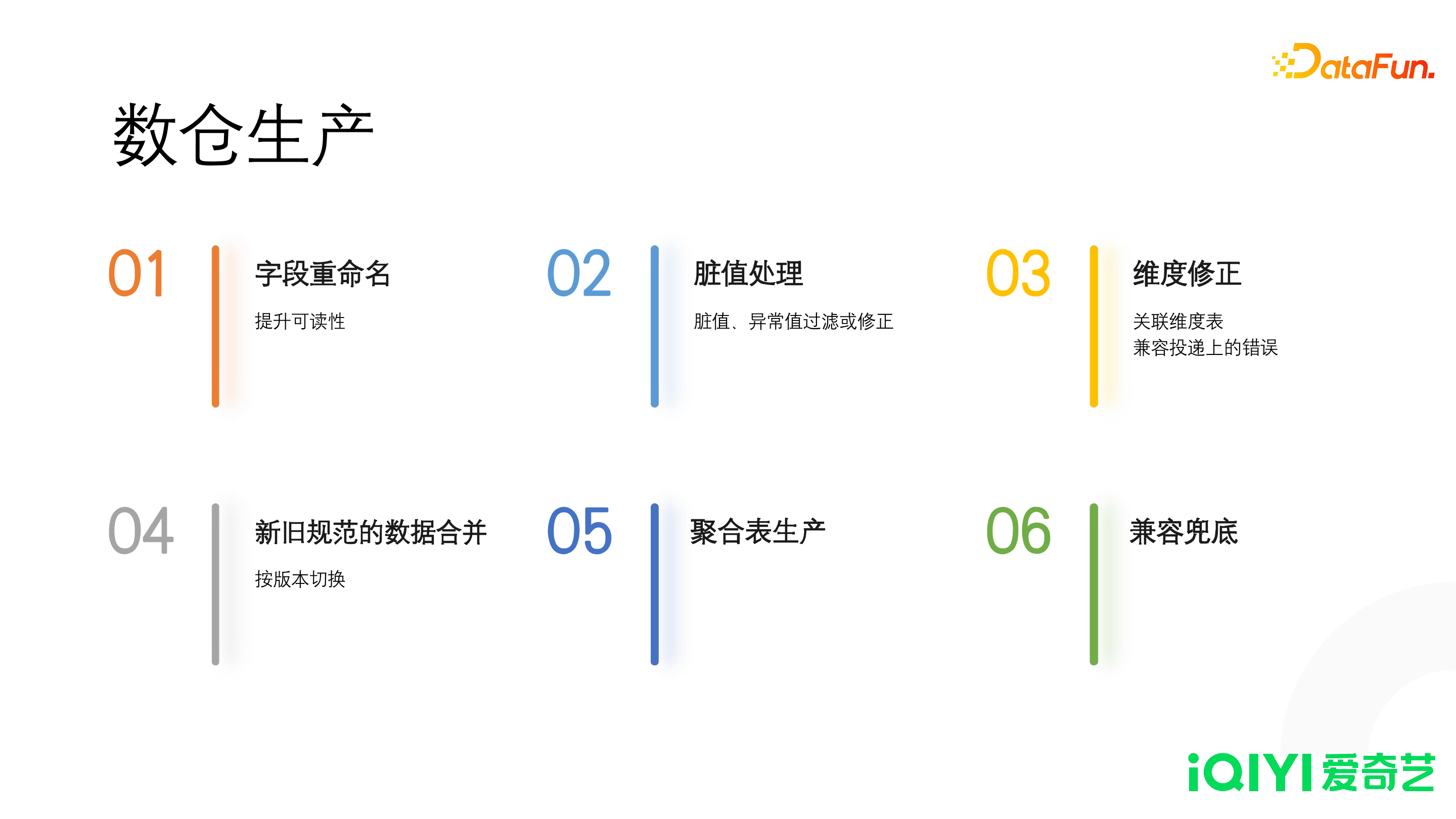
- 字段重命名
- 投递使用的字段为了复用,都是用单个字母命名的。我们在数仓进行了字段的重命名,使用完整的英文单词来提升可读性。
- 脏值处理
- 对于异常数据或者脏值,我们在数仓生产中进行过滤或者修正。
- 维度修正
- 由于不可控的原因,导致某些维度值可能投不上来。可以通过关联维度表来补齐空值,从而提升数据质量。
- 新旧规范的数据合并
- 我们通过版本切换的方式,把新埋点的数据和旧埋点的数据在数仓生产这一层进行合并。数仓表的下游对新旧版本数据的切换是无感知的。
- 聚合表生产
- 保留关键的字段,聚合指标和维度,在某些计算场景可以极大减少资源的消耗。
- 兼容兜底
- 除了上面提到的一些错误之外,如果投递上发生了任何的问题,可以在数仓层进行兜底。
05
正在做的改进
目前正在改进的方面主要包括:
- 结合数据开发平台,分析生产逻辑,建立数据的上下游关系。
- 生产变更通知。
- 是否有下游消费,适时停止生产,降低资源消耗。
- 字段血缘,通知统计口径的变更。
以上就是本次分享的内容,谢谢大家。
文章来源: DataFunSummit微信公众号